
Appearance
分段
linux并没有利用分段实现虚拟内存, 但是却利用了dpl功能实现了权限控制. 用户态DPL是3, 内核态DPL是0, 当用户态程序 CPL为3时直接访问内核态的地址时,会因权限不足而报错。所以要通过syscal, int等特别指令触发切换, 这些指令会改变CPL值
c
DEFINE_PER_CPU_PAGE_ALIGNED(struct gdt_page, gdt_page) = { .gdt = {
/*
* We need valid kernel segments for data and code in long mode too
* IRET will check the segment types kkeil 2000/10/28
* Also sysret mandates a special GDT layout
*
* TLS descriptors are currently at a different place compared to i386.
* Hopefully nobody expects them at a fixed place (Wine?)
*/
[GDT_ENTRY_KERNEL32_CS] = GDT_ENTRY_INIT(0xc09b, 0, 0xfffff),
[GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xa09b, 0, 0xfffff),
[GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc093, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER32_CS] = GDT_ENTRY_INIT(0xc0fb, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f3, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xa0fb, 0, 0xfffff),
} };虚拟地址映射
x86_64下面分页机制采用四级目录, 相关数据结构在arch/x86/include/asm/pgtable_64_types.h 如果cpu支持5级分页, 当前centos9会自动激活这个特性
c
#define PGDIR_SHIFT 39
#define PTRS_PER_PGD 512
/*
* 3rd level page
*/
#define PUD_SHIFT 30
#define PTRS_PER_PUD 512
/*
* PMD_SHIFT determines the size of the area a middle-level
* page table can map
*/
#define PMD_SHIFT 21
#define PTRS_PER_PMD 512
/*
* entries per page directory level
*/
#define PTRS_PER_PTE 512
#define PMD_SIZE (_AC(1, UL) << PMD_SHIFT)
#define PMD_MASK (~(PMD_SIZE - 1))
#define PUD_SIZE (_AC(1, UL) << PUD_SHIFT)
#define PUD_MASK (~(PUD_SIZE - 1))
#define PGDIR_SIZE (_AC(1, UL) << PGDIR_SHIFT)
#define PGDIR_MASK (~(PGDIR_SIZE - 1))x86_64的虚拟地址是64位, 但只使用48位用于映射到物理地址.因为处理器地址只有48条,要求内存地址48位到63位必须相同, 具体四级目录用到的位数如下:
PGD(9) + PUD(9) + PMD(9) + PTE(9) + 页内偏移(12)
查询当前系统一页的大小
bash
[root@localhost ~]# getconf PAGE_SIZE
4096进程空间
进程空间分为用户态地址空间和内核态地址空间, 32位下面用户态空间是3G, 内核态时1G. 分界线为宏#define TASK_SIZE, 这个定义了用户态空间的最大地址, 根据下面的宏, 计算出x86_64下面为0x00007FFFFFFFF000
c
#define TASK_SIZE (test_thread_flag(TIF_ADDR32) ? \
IA32_PAGE_OFFSET : TASK_SIZE_MAX)
#define TASK_SIZE_MAX ((1UL << __VIRTUAL_MASK_SHIFT) - PAGE_SIZE)
#ifdef CONFIG_X86_5LEVEL
#define __VIRTUAL_MASK_SHIFT (pgtable_l5_enabled() ? 56 : 47)
#else
#define __VIRTUAL_MASK_SHIFT 47
#endifcrash> struct mm_struct -x 0xffff99da00e79540 | grep size
task_size = 0x7ffffffff000,
crash>x86_64下
用户空间 0x0000000000000000 ~ 0x00007FFFFFFFF000 128T
内核空间 0xFFFF800000000000 ~ 0xFFFFFFFFFFFFFFFF 128T
0x00007FFFFFFFF000 到 0xFFFF800000000000 为空洞区域
在execve时,将该值设置到mm_struct上面去
c
/* Set the new mm task size. We have to do that late because it may
* depend on TIF_32BIT which is only updated in flush_thread() on
* some architectures like powerpc
*/
current->mm->task_size = TASK_SIZE;bash
crash> struct mm_struct.task_size -x 0xffff9f814be29f80
task_size = 0x7ffffffff000
crash>在x86_64, 内核态从0xffff888000000000 开始映射整个物理内存
c
#define __PAGE_OFFSET_BASE_L4 _AC(0xffff888000000000, UL)
#ifdef CONFIG_DYNAMIC_MEMORY_LAYOUT
#define __PAGE_OFFSET page_offset_base如果打开了kaslr, 在kernel_randomize_memory里会对page_offset_base随机向上偏移一些位置, 如下是实际运行的cents8里的值:
bash
crash> px page_offset_base
page_offset_base = $20 = 0xffff9f7f40000000
crash>参考文档: Documentation/x86/x86_64/mm.txt
用户态
在load_elf_binary函数里 setup_new_exec里设置mm->mmap_base和mm->task_size, kernel.randomize_va_space = 2表示需要随机化部分区域的起始地址, 包括mmap, stack等setup_arg_pages里设置mm->arg_start和mm->start_stack, 此时这两个值一样create_elf_tables 重新设置了mm->start_stack
start_stack指栈底, 它与arg_start之前存放了一些信息, 比如执行命令的参数个数和每一个参数的具体字符串指针, 每一个环境变量的指针. arg_start ~ arg_end, env_start ~ env_end 之间才是真正存放这些数据的地方. 在程序内部改变这些指针值就能改变参数和环境变量信息
内核态
page_offset_base开始的64T范围内是直接映射内存, 这些虚拟地址对应的物理地址就是 减去page_offset_base
page_offset_base默认是0xffff888000000000, 如果CONFIG_RANDOMIZE_MEMORY=y则会随机偏移些
每个进程对应的task_struct分配在这个区域, 可以减去page_offset_base直接得到物理地址
crash> vtop ffff9e68002398c0
VIRTUAL PHYSICAL
ffff9e68002398c0 1002398c0
PGD DIRECTORY: ffffffffb2e10000
PAGE DIRECTORY: 1c601067
PUD: 1c601d00 => 1c606067
PMD: 1c606008 => 1057a9063
PTE: 1057a91c8 => 8000000100239063
PAGE: 100239000
PTE PHYSICAL FLAGS
8000000100239063 100239000 (PRESENT|RW|ACCESSED|DIRTY|NX)
PAGE PHYSICAL MAPPING INDEX CNT FLAGS
ffffdba004008e40 100239000 dead000000000008 0 0 17ffffc0000000
crash> px page_offset_base
page_offset_base = $15 = 0xffff9e6700000000
crash> eval ffff9e68002398c0 - 0xffff9e6700000000
hexadecimal: 1002398c0
decimal: 4297300160
octal: 40010714300
binary: 0000000000000000000000000000000100000000001000111001100011000000
crash>vmalloc_base从 0xffffc90000000000UL开始, 随机偏移后, 可通过如下命令获取当前值
crash> px vmalloc_base
vmalloc_base = $16 = 0xffffb9cb00000000
crash>vmemmap_base从 0xffffea0000000000UL开始, 随机偏移后, 可通过如下命令获取当前值, 存放 struct page
crash> px vmemmap_base
vmemmap_base = $17 = 0xffffdba000000000
crash>内核的代码段从__START_KERNEL_map开始, 对应的物理地址是减去 __START_KERNEL_map 加上 phys_base
c
#define __START_KERNEL_map _AC(0xffffffff80000000, UL)物理分配
当前主流都是numa结构, 即一个CPU对应本地内存, 当本地内存不够, 再通过总线访问其他节点的内存. 内存管理的最小单位是页, 通常是4K, 它属于Zone, Zone属于node节点节. node节点就是numa节点
如下表示该OS可以支持 1<< 10 == 1024个numa节点
bash
[root@localhost ~]# grep CONFIG_NODES_SHIFT /boot/config-5.14.0-22.el9.x86_64
CONFIG_NODES_SHIFT=10一台4u8G的机器, 只有一个numa. cpu0~3属于node0
bash
[root@localhost ~]# lscpu | grep NUMA
NUMA node(s): 1
NUMA node0 CPU(s): 0-3node0里面的跟物理内存的相关的数据如下
c
struct pglist_data *node_data[MAX_NUMNODES] __read_mostly;
EXPORT_SYMBOL(node_data);crash> p node_data[0]
$22 = (pg_data_t *) 0xffff94e6dffd1000
crash> struct pg_data_t.node_id,nr_zones,node_start_pfn,node_present_pages,node_spanned_pages -x 0xffff94e6dffd1000
node_id = 0x0,
nr_zones = 0x3,
node_start_pfn = 0x1, //从页号1开始
node_present_pages = 0x1fff8e, //该node管理0x1fff8e个可用的页.
node_spanned_pages = 0x21ffff, //管理0x21ffff页(8G), 除了包含present_pages, 还包含了空洞的物理地址. 这些页不可用.
crash> struct zone.name,zone_start_pfn,spanned_pages,present_pages,managed_pages -x ffff94e6dffd1000 5
name = 0xffffffffa9fa3ed3 "DMA",
zone_start_pfn = 0x1,
spanned_pages = 0xfff,
present_pages = 0xf9e,
managed_pages = {
counter = 0xf00
},
name = 0xffffffffa9f4c32c "DMA32",
zone_start_pfn = 0x1000,
spanned_pages = 0xff000,
present_pages = 0xdeff0,
managed_pages = {
counter = 0xcaff0
},
name = 0xffffffffa9f4c222 "Normal",
zone_start_pfn = 0x100000,
spanned_pages = 0x120000,
present_pages = 0x120000,
managed_pages = {
counter = 0x1145ec
},
name = 0xffffffffa9f4c229 "Movable",
zone_start_pfn = 0x0,
spanned_pages = 0x0,
present_pages = 0x0,
managed_pages = {
counter = 0x0
},
name = 0xffffffffa9f9924d "Device",
zone_start_pfn = 0x0,
spanned_pages = 0x0,
present_pages = 0x0,
managed_pages = {
counter = 0x0
},
crash>0x1fff8e个可用页等于 8388152K
[root@localhost ~]# dmesg -T | grep Mem
[Sun Dec 26 11:12:09 2021] Memory: 3442876K/8388152K available (14345K kernel code, 5931K rwdata, 8944K rodata, 2656K init, 5448K bss, 556100K reserved, 0K cma-reserved)上面可以看到64位下有三个zone, 分别是 DMA, DMA32, Normal
struct page代表一页, 页通过伙伴系统管理. 所有空闲页挂在11个页块链表上. 每个链表包含相同连续页的地址. 有 1、2、4、8、16、32、64、128、256、512 和 1024. 所以一次最大可申请1024个物理地址连续的页(即4M的内存). 这些链表存在struct zone.free_area
第 i 个页块链表中,页块中页的数目为 2^i
c
#define MAX_ORDER 11order为i时, 意味着申请 2 ^ i 个连续页, 如果free_area[i]没有, 则去free_area[i+1]里面找, 依次类推
物理内存
系统启动时,从BIOS读取物理内存的分布信息,软件层面先通过memblock分配必要的内存,后续通过buddy作为整个内存的唯一分配器。 如下是一台32u64G(两个numa)虚拟机dmesg部分跟物理内存分配有关的日志,后续的代码梳理会结合这些日志。
[Tue Nov 4 21:29:37 2025] Linux version 5.14.0-505.el9.x86_64 (mockbuild@x86-05.stream.rdu2.redhat.com) (gcc (GCC) 11.5.0 20240719 (Red Hat 11.5.0-2), GNU ld version 2.35.2-54.el9) #1 SMP
PREEMPT_DYNAMIC Thu Sep 5 07:54:07 UTC 2024
[Tue Nov 4 21:29:37 2025] The list of certified hardware and cloud instances for Red Hat Enterprise Linux 9 can be viewed at the Red Hat Ecosystem Catalog, https://catalog.redhat.com.
[Tue Nov 4 21:29:37 2025] Command line: BOOT_IMAGE=(hd0,msdos1)/boot/vmlinuz-5.14.0-505.el9.x86_64 root=UUID=dc2ec1e2-2e1d-4df4-837b-85cadfdb2ac4 ro net.ifnames=0 consoleblank=600 console
=tty0 console=ttyS0,115200n8 selinux=0 crashkernel=2G-64G:256M,64G-:512M
[Tue Nov 4 21:29:37 2025] BIOS-provided physical RAM map:
[Tue Nov 4 21:29:37 2025] BIOS-e820: [mem 0x0000000000000000-0x000000000009fbff] usable
[Tue Nov 4 21:29:37 2025] BIOS-e820: [mem 0x000000000009fc00-0x000000000009ffff] reserved
[Tue Nov 4 21:29:37 2025] BIOS-e820: [mem 0x00000000000f0000-0x00000000000fffff] reserved
[Tue Nov 4 21:29:37 2025] BIOS-e820: [mem 0x0000000000100000-0x00000000bff7ffff] usable
[Tue Nov 4 21:29:37 2025] BIOS-e820: [mem 0x00000000bff80000-0x00000000bfffffff] reserved
[Tue Nov 4 21:29:37 2025] BIOS-e820: [mem 0x00000000feffc000-0x00000000feffffff] reserved
[Tue Nov 4 21:29:37 2025] BIOS-e820: [mem 0x00000000fffc0000-0x00000000ffffffff] reserved
[Tue Nov 4 21:29:37 2025] BIOS-e820: [mem 0x0000000100000000-0x000000103fffffff] usable
[Tue Nov 4 21:29:37 2025] e820: update [mem 0x00000000-0x00000fff] usable ==> reserved
[Tue Nov 4 21:29:37 2025] e820: remove [mem 0x000a0000-0x000fffff] usable
[Tue Nov 4 21:29:37 2025] last_pfn = 0x1040000 max_arch_pfn = 0x400000000
[Tue Nov 4 21:29:37 2025] last_pfn = 0xbff80 max_arch_pfn = 0x400000000
[Tue Nov 4 21:29:37 2025] found SMP MP-table at [mem 0x000f6a40-0x000f6a4f]
[Tue Nov 4 21:29:37 2025] Using GB pages for direct mapping
[Tue Nov 4 21:29:37 2025] RAMDISK: [mem 0x33f7a000-0x35fb4fff]
[Tue Nov 4 21:29:37 2025] ACPI: SRAT: Node 0 PXM 0 [mem 0x00000000-0x0009ffff]
[Tue Nov 4 21:29:37 2025] ACPI: SRAT: Node 0 PXM 0 [mem 0x00100000-0xbfffffff]
[Tue Nov 4 21:29:37 2025] ACPI: SRAT: Node 0 PXM 0 [mem 0x100000000-0x83fffffff]
[Tue Nov 4 21:29:37 2025] ACPI: SRAT: Node 1 PXM 1 [mem 0x840000000-0x103fffffff]
[Tue Nov 4 21:29:37 2025] NUMA: Node 0 [mem 0x00000000-0x0009ffff] + [mem 0x00100000-0xbfffffff] -> [mem 0x00000000-0xbfffffff]
[Tue Nov 4 21:29:37 2025] NUMA: Node 0 [mem 0x00000000-0xbfffffff] + [mem 0x100000000-0x83fffffff] -> [mem 0x00000000-0x83fffffff]
[Tue Nov 4 21:29:37 2025] NODE_DATA(0) allocated [mem 0x83ffd5000-0x83fffffff]
[Tue Nov 4 21:29:37 2025] NODE_DATA(1) allocated [mem 0x103ffd5000-0x103fffffff]
[Tue Nov 4 21:29:37 2025] Reserving 512MB of memory at 2544MB for crashkernel (System RAM: 65535MB)
[Tue Nov 4 21:29:37 2025] Zone ranges:
[Tue Nov 4 21:29:37 2025] DMA [mem 0x0000000000001000-0x0000000000ffffff]
[Tue Nov 4 21:29:37 2025] DMA32 [mem 0x0000000001000000-0x00000000ffffffff]
[Tue Nov 4 21:29:37 2025] Normal [mem 0x0000000100000000-0x000000103fffffff]
[Tue Nov 4 21:29:37 2025] Device empty
[Tue Nov 4 21:29:37 2025] Movable zone start for each node
[Tue Nov 4 21:29:37 2025] Early memory node ranges
[Tue Nov 4 21:29:37 2025] node 0: [mem 0x0000000000001000-0x000000000009efff]
[Tue Nov 4 21:29:37 2025] node 0: [mem 0x0000000000100000-0x00000000bff7ffff]
[Tue Nov 4 21:29:37 2025] node 0: [mem 0x0000000100000000-0x000000083fffffff]
[Tue Nov 4 21:29:37 2025] node 1: [mem 0x0000000840000000-0x000000103fffffff]
[Tue Nov 4 21:29:37 2025] Initmem setup node 0 [mem 0x0000000000001000-0x000000083fffffff]
[Tue Nov 4 21:29:37 2025] Initmem setup node 1 [mem 0x0000000840000000-0x000000103fffffff]
[Tue Nov 4 21:29:37 2025] On node 0, zone DMA: 1 pages in unavailable ranges
[Tue Nov 4 21:29:37 2025] On node 0, zone DMA: 97 pages in unavailable ranges
[Tue Nov 4 21:29:37 2025] On node 0, zone Normal: 128 pages in unavailable ranges
[Tue Nov 4 21:29:37 2025] [mem 0xc0000000-0xfeffbfff] available for PCI devices
[Tue Nov 4 21:29:37 2025] Fallback order for Node 0: 0 1
[Tue Nov 4 21:29:37 2025] Fallback order for Node 1: 1 0
[Tue Nov 4 21:29:37 2025] Built 2 zonelists, mobility grouping on. Total pages: 16514690
[Tue Nov 4 21:29:37 2025] Policy zone: Normal
[Tue Nov 4 21:29:37 2025] mem auto-init: stack:off, heap alloc:off, heap free:off
[Tue Nov 4 21:29:37 2025] software IO TLB: area num 32.
[Tue Nov 4 21:29:37 2025] Memory: 2783248K/67107960K available (16384K kernel code, 5657K rwdata, 12972K rodata, 3980K init, 5696K bss, 1735036K reserved, 0K cma-reserved)
[Tue Nov 4 21:29:37 2025] Freeing SMP alternatives memory: 40K
[Tue Nov 4 21:29:38 2025] Freeing initrd memory: 33004K
[Tue Nov 4 21:29:38 2025] Freeing unused decrypted memory: 2028K
[Tue Nov 4 21:29:38 2025] Freeing unused kernel image (initmem) memory: 3980K
[Tue Nov 4 21:29:38 2025] Freeing unused kernel image (rodata/data gap) memory: 1364KOS启动时内存初始化相关函数流程如下:
c
start_kernel()
setup_arch() // arch/x86/kernel/setup.c
early_reserve_memory() //
e820__memory_setup() // 从bios硬件获取内存物理分布,并打印
trim_bios_range() // 对特殊的部分物理区间进行预留
e820__end_of_ram_pfn() // 获取可用内存里最大的物理页框号
kernel_randomize_memory() // 直接映射,vmalloc,vmemmap的基址随机化
reserve_brk() // 预留brk的内存
e820__memblock_setup() // 遍历从e820读取的内存分布,加入到memblock里
init_mem_mapping() // 完成 vaddr == paddr + PAGE_OFFSET 的映射关系
init_memory_mapping()
memory_map_top_down() // 从高地址到低地址,实现直接映射
load_cr3(swapper_pg_dir) // 切换页表的根地址
initmem_init()
x86_numa_init() // 从ACPI获取numa与物理地址的关系,同时分配pg_data_t
reserve_crashkernel() // 预留用于panic时生成vmcore
x86_init.paging.pagetable_init() // 开始物理内存对应的page初始化
sparse_init() // 采用sparse模式初始化
memblocks_present() // 生成mem_section管理固定数量的物理内存区间
sparse_init_nid() // 为每一个mem_section管理的物理内存分配对应的struct page,并映射
zone_sizes_init() // 初始化zone
free_area_init()
free_area_init_node() // 初始化 pg_data_t
calculate_node_totalpages() // 计算zone里spanned,absent的pages数量
free_area_init_core() // 继续完成初始化 pg_data_t
memmap_init() // 初始化对应的struct page
mm_core_init()
build_all_zonelists() // 建立zonelist
mem_init() //
memblock_free_all() // memblock里可用且没有预留的内存全部放到zone的freelist里
reset_all_zones_managed_pages() // 每个zone里的managed page清零
free_low_memory_core_early()
memmap_init_reserved_pages() // memblock里预留的内存对应的page初始化并设置标志位reserved
__free_memory_core()
mem_init_print_info() // 打印信息
kmem_cache_init() // 初始化slab从硬件获取物理内存信息
x86_64架构,通过bios启动的OS,可通过e820获取真实的物理内存分布和其地址,如下打印显示有4个区间可用, 5个区间属于硬件预留,OS无法使用。
[Tue Nov 4 21:29:37 2025] BIOS-provided physical RAM map:
[Tue Nov 4 21:29:37 2025] BIOS-e820: [mem 0x0000000000000000-0x000000000009fbff] usable
[Tue Nov 4 21:29:37 2025] BIOS-e820: [mem 0x000000000009fc00-0x000000000009ffff] reserved
[Tue Nov 4 21:29:37 2025] BIOS-e820: [mem 0x00000000000f0000-0x00000000000fffff] reserved
[Tue Nov 4 21:29:37 2025] BIOS-e820: [mem 0x0000000000100000-0x00000000bff7ffff] usable
[Tue Nov 4 21:29:37 2025] BIOS-e820: [mem 0x00000000bff80000-0x00000000bfffffff] reserved
[Tue Nov 4 21:29:37 2025] BIOS-e820: [mem 0x00000000feffc000-0x00000000feffffff] reserved
[Tue Nov 4 21:29:37 2025] BIOS-e820: [mem 0x00000000fffc0000-0x00000000ffffffff] reserved
[Tue Nov 4 21:29:37 2025] BIOS-e820: [mem 0x0000000100000000-0x000000103fffffff] usable这些信息除了在dmesg日志里打印,后续也可以在/sys下面查询, 请注意OS在后续的启动过程会修改数据,但/sys里 显示的就是原始硬件上报的未经修改的数据。
[root@localhost memmap]# grep "" /sys/firmware/memmap/*/*
/sys/firmware/memmap/0/end:0x9fbff
/sys/firmware/memmap/0/start:0x0
/sys/firmware/memmap/0/type:System RAM
/sys/firmware/memmap/1/end:0x9ffff
/sys/firmware/memmap/1/start:0x9fc00
/sys/firmware/memmap/1/type:Reserved
/sys/firmware/memmap/2/end:0xfffff
/sys/firmware/memmap/2/start:0xf0000
/sys/firmware/memmap/2/type:Reserved
/sys/firmware/memmap/3/end:0xbff7ffff
/sys/firmware/memmap/3/start:0x100000
/sys/firmware/memmap/3/type:System RAM
/sys/firmware/memmap/4/end:0xbfffffff
/sys/firmware/memmap/4/start:0xbff80000
/sys/firmware/memmap/4/type:Reserved
/sys/firmware/memmap/5/end:0xfeffffff
/sys/firmware/memmap/5/start:0xfeffc000
/sys/firmware/memmap/5/type:Reserved
/sys/firmware/memmap/6/end:0xffffffff
/sys/firmware/memmap/6/start:0xfffc0000
/sys/firmware/memmap/6/type:Reserved
/sys/firmware/memmap/7/end:0x103fffffff
/sys/firmware/memmap/7/start:0x100000000
/sys/firmware/memmap/7/type:System RAM在trim_bios_range继续预留两个特殊区域
[Tue Nov 4 21:29:37 2025] e820: update [mem 0x00000000-0x00000fff] usable ==> reserved
[Tue Nov 4 21:29:37 2025] e820: remove [mem 0x000a0000-0x000fffff] usablememblock
通过在cmdline增加 memblock=debug 可以打印更多memblock的分配/释放信息
memblock里有两种类型的内存区间信息,可用的和预留的。但memblock里的预留跟e820里的预留内存没有关系, memblock里的预留可以理解 为在memblock可用内存区间里已申请被使用的内存,即非空闲内存
在e820__memblock_setup里将e820里记录usable内存加入到memblock里,打印的信息如下,3个在e820里的usable内存区间全部加入进去, 预留显示的4个,都是在early_reserve_memory里预留的。第三个是initrd的内存, 第四个是kernel的内存。
[Tue Nov 4 23:50:06 2025] MEMBLOCK configuration:
[Tue Nov 4 23:50:06 2025] memory size = 0x0000000ffff1ec00 reserved size = 0x00000000052bd000
[Tue Nov 4 23:50:06 2025] memory.cnt = 0x3
[Tue Nov 4 23:50:06 2025] memory[0x0] [0x0000000000001000-0x000000000009efff], 0x000000000009e000 bytes flags: 0x0
[Tue Nov 4 23:50:06 2025] memory[0x1] [0x0000000000100000-0x00000000bff7ffff], 0x00000000bfe80000 bytes flags: 0x0
[Tue Nov 4 23:50:06 2025] memory[0x2] [0x0000000100000000-0x000000103fffffff], 0x0000000f40000000 bytes flags: 0x0
[Tue Nov 4 23:50:06 2025] reserved.cnt = 0x4
[Tue Nov 4 23:50:06 2025] reserved[0x0] [0x0000000000000000-0x000000000000ffff], 0x0000000000010000 bytes flags: 0x0
[Tue Nov 4 23:50:06 2025] reserved[0x1] [0x000000000009f000-0x00000000000fffff], 0x0000000000061000 bytes flags: 0x0
[Tue Nov 4 23:50:06 2025] reserved[0x2] [0x0000000033f7a000-0x0000000035fb4fff], 0x000000000203b000 bytes flags: 0x0
[Tue Nov 4 23:50:06 2025] reserved[0x3] [0x0000000b9fa00000-0x0000000ba2c10fff], 0x0000000003211000 bytes flags: 0x0从memblock的debug日志可以看到在进入buddy前内核做了很多必要的内存分配以满足初始化,其中size最大的两处是:
reserve_crashkernel里申请内存用于panic时启动第二内核
Reserving 512MB of memory at 2544MB for crashkernel (System RAM: 65535MB)sparse_init里为物理内存分配对应的struct page, 可通过memblock的debug日志观察到类似如下的打印
[Tue Nov 4 23:50:06 2025] memblock_alloc_exact_nid_raw: 536870912 bytes align=0x200000 nid=0 from=0x0000000001000000 max_addr=0x0000000000000000 sparse_init_nid+0x11b/0x234
[Tue Nov 4 23:50:06 2025] memblock_reserve: [0x000000081fe00000-0x000000083fdfffff] memblock_alloc_range_nid+0xaf/0x14c
[Tue Nov 4 23:50:06 2025] memblock_alloc_exact_nid_raw: 536870912 bytes align=0x200000 nid=1 from=0x0000000001000000 max_addr=0x0000000000000000 sparse_init_nid+0x11b/0x234
[Tue Nov 4 23:50:06 2025] memblock_reserve: [0x000000101fe00000-0x000000103fdfffff] memblock_alloc_range_nid+0xaf/0x14c假设物理内存64G, struct page 结构体是 64 bytes, 大致需要 64 * 1024 * 1024 / 4 * 64 = 1G 的内存
初始化zonelist
内存分配,先从当前node的zone分配,如果没有内存,则fallback到其他node去,如下日志打印了遍历顺序,基于 node 之前的distance计算而来, 比如node 1, 先从node1分配,不满足则去node 0上面寻找空闲内存。
[Tue Nov 4 21:29:37 2025] Fallback order for Node 0: 0 1
[Tue Nov 4 21:29:37 2025] Fallback order for Node 1: 1 0find_next_best_node不断返回下一个最优的node, 生成列表, build_zonelists_in_node_order生成ZONELIST_FALLBACK 的遍历顺序,build_thisnode_zonelists生成ZONELIST_NOFALLBACK的遍历列表
c
static void build_zonelists(pg_data_t *pgdat)
{
static int node_order[MAX_NUMNODES];
int node, nr_nodes = 0;
nodemask_t used_mask = NODE_MASK_NONE;
int local_node, prev_node;
/* NUMA-aware ordering of nodes */
local_node = pgdat->node_id;
prev_node = local_node;
memset(node_order, 0, sizeof(node_order));
while ((node = find_next_best_node(local_node, &used_mask)) >= 0) {
node_order[nr_nodes++] = node;
prev_node = node;
}
build_zonelists_in_node_order(pgdat, node_order, nr_nodes);
build_thisnode_zonelists(pgdat);
pr_info("Fallback order for Node %d: ", local_node);
for (node = 0; node < nr_nodes; node++)
pr_cont("%d ", node_order[node]);
pr_cont("\n");
}Buddy系统
下面日志显示内存与numa之间的亲和性,同时表示node的结构体是在node自身对应的内存区间分配。
[Tue Nov 4 21:29:37 2025] ACPI: SRAT: Node 0 PXM 0 [mem 0x00000000-0x0009ffff]
[Tue Nov 4 21:29:37 2025] ACPI: SRAT: Node 0 PXM 0 [mem 0x00100000-0xbfffffff]
[Tue Nov 4 21:29:37 2025] ACPI: SRAT: Node 0 PXM 0 [mem 0x100000000-0x83fffffff]
[Tue Nov 4 21:29:37 2025] ACPI: SRAT: Node 1 PXM 1 [mem 0x840000000-0x103fffffff]
[Tue Nov 4 21:29:37 2025] NUMA: Node 0 [mem 0x00000000-0x0009ffff] + [mem 0x00100000-0xbfffffff] -> [mem 0x00000000-0xbfffffff]
[Tue Nov 4 21:29:37 2025] NUMA: Node 0 [mem 0x00000000-0xbfffffff] + [mem 0x100000000-0x83fffffff] -> [mem 0x00000000-0x83fffffff]
[Tue Nov 4 21:29:37 2025] NODE_DATA(0) allocated [mem 0x83ffd5000-0x83fffffff]
[Tue Nov 4 21:29:37 2025] NODE_DATA(1) allocated [mem 0x103ffd5000-0x103fffffff]node zone
在典型的x86_64上面,只有DMZ,DMZ32,Nornal三个zone, DMA,DMZ32都有自身的对于内存区间的特定要求,整体 三个zone对应的内存区间是从小到大,具备连续性的。它把整个内存看出线性的,连续的。很明显node1的zone里没有DMA和DMA32。
[Tue Nov 4 21:29:37 2025] Zone ranges:
[Tue Nov 4 21:29:37 2025] DMA [mem 0x0000000000001000-0x0000000000ffffff]
[Tue Nov 4 21:29:37 2025] DMA32 [mem 0x0000000001000000-0x00000000ffffffff]
[Tue Nov 4 21:29:37 2025] Normal [mem 0x0000000100000000-0x000000103fffffff]
[Tue Nov 4 21:29:37 2025] Device empty
[Tue Nov 4 21:29:37 2025] Movable zone start for each node
[Tue Nov 4 21:29:37 2025] Early memory node ranges
[Tue Nov 4 21:29:37 2025] node 0: [mem 0x0000000000001000-0x000000000009efff]
[Tue Nov 4 21:29:37 2025] node 0: [mem 0x0000000000100000-0x00000000bff7ffff]
[Tue Nov 4 21:29:37 2025] node 0: [mem 0x0000000100000000-0x000000083fffffff]
[Tue Nov 4 21:29:37 2025] node 1: [mem 0x0000000840000000-0x000000103fffffff]
[Tue Nov 4 21:29:37 2025] Initmem setup node 0 [mem 0x0000000000001000-0x000000083fffffff]
[Tue Nov 4 21:29:37 2025] Initmem setup node 1 [mem 0x0000000840000000-0x000000103fffffff]node 与 zone 的关系如下图,所有的空闲页按页框号分别挂在每个zone下面。 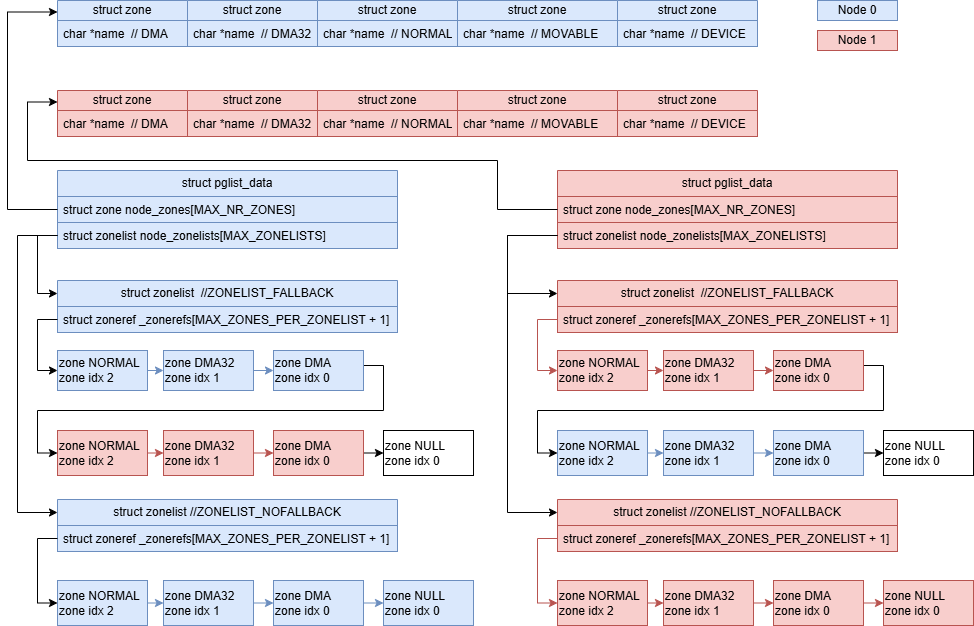
实际查询/proc/zoneinfo, Node1确实没有DMA,DMA32 zone
[root@localhost ~]# grep -E "Node|spanned|present|managed" /proc/zoneinfo
Node 0, zone DMA
spanned 4095
present 3998
managed 3840
Node 0, zone DMA32
spanned 1044480
present 782208
managed 634752
Node 0, zone Normal
spanned 7602176
present 7602176
managed 7470028
Node 0, zone Movable
spanned 0
present 0
managed 0
Node 0, zone Device
spanned 0
present 0
managed 0
Node 1, zone DMA
spanned 0
present 0
managed 0
Node 1, zone DMA32
spanned 0
present 0
managed 0
Node 1, zone Normal
spanned 8388608
present 8388608
managed 8244716
Node 1, zone Movable
spanned 0
present 0
managed 0
Node 1, zone Device
spanned 0
present 0
managed 0struct zone里字段解释: spanned_pages:上面zone range范围内的页数 present_pages:memblock里可用内存在该zone range范围内的内存对应的页数 managed_pages:present_pages里减去memblock 预留的内存后对应的页数
c
calculate_node_totalpages()
zone_spanned_pages_in_node() // zone对应的range
zone_absent_pages_in_node() // zone对应的range - memblock里的在zone range 范围内的可用内存
free_area_init_core()
zone_init_internals() // 设置managed_pages但后续会被reset 为0, 基本没啥用
memblock_free_all() // 函数结束时将page数加入到 _totalram_pages里
reset_all_zones_managed_pages() // managed_page清零
free_low_memory_core_early()
memmap_init_reserved_pages()
__free_memory_core()
__free_pages_memory()
memblock_free_pages() // order为10,也就是最大值释放page
__free_pages_core() // 增加zone里的managed_page各zone里present_pages的总和是E820显示的可用内存(usable 内存)总和。 各zone里managed_pages的总和就是buddy可用于分配的总页数。 sum(managed_pages) == MemTotal in /proc/meminfo == _totalram_pages(kernel global variable)
[root@localhost ~]# grep managed /proc/zoneinfo | awk '{sum+=$2} END{print sum*4}'
65413344
[root@localhost ~]# head -1 /proc/meminfo
MemTotal: 65413344 kB
[root@localhost ~]#
extern atomic_long_t _totalram_pages;
static inline unsigned long totalram_pages(void)
{
return (unsigned long)atomic_long_read(&_totalram_pages);
}[Tue Nov 4 23:50:06 2025] Memory: 2783248K/67107960K available (16384K kernel code, 5657K rwdata, 12972K rodata, 3980K init, 5696K bss, 1735032K reserved, 0K cma-reserved)2783248K代表可用内存, 但信息不准, 在该补丁里修复 https://github.com/torvalds/linux/commit/4f66da89d31ca56d4c41de01dd663f79d697904b
67107960K 代表 present_pages的总和
[root@localhost ~]# grep present /proc/zoneinfo | awk '{sum+=$2} END{print sum*4}'
671079601735036K reserved 在打印该日志时预留的内存,后续又释放了一些内存,所以最终的预留内存会减少些,准确的数字为 67107960 - 65413344 = 1694616K 1735032 - 40 - 33004 - 2028 - 3980 - 1364 = 1694616K
[root@localhost ~]# grep present /proc/zoneinfo | awk '{sum+=$2} END{print sum*4}'
67107960
[root@localhost ~]# grep managed /proc/zoneinfo | awk '{sum+=$2} END{print sum*4}'
65413344
[root@localhost ~]# dmesg -T | grep -E "Memory:|Free"
[Tue Nov 4 23:50:06 2025] Memory: 2783248K/67107960K available (16384K kernel code, 5657K rwdata, 12972K rodata, 3980K init, 5696K bss, 1735032K reserved, 0K cma-reserved)
[Tue Nov 4 23:50:06 2025] Freeing SMP alternatives memory: 40K
[Tue Nov 4 23:50:07 2025] Freeing initrd memory: 33004K
[Tue Nov 4 23:50:08 2025] Freeing unused decrypted memory: 2028K
[Tue Nov 4 23:50:08 2025] Freeing unused kernel image (initmem) memory: 3980K
[Tue Nov 4 23:50:08 2025] Freeing unused kernel image (rodata/data gap) memory: 1364K页释放
不管是memblock代表的内存转换为buddy时或者后续的内存释放过程,最终都是走到 __free_one_page。伙伴算法的特点是分配时 从order对应的空闲列表里找,如果没就将order+1的内存切成两个,一个放到order里,一个用于分配。 释放时先检查邻居页 是否空闲,如果是则合并,继续在order+1里找是否有邻居,直到无法合并时在放入对应order的空闲列表里。
找邻居的算法举例: 假设有物理页 0 1 2 3 4 5 6 7 8 9
页 2 order 2 的 邻居是 2 ^ 1<<2 = 6 页 6 order 2 的 邻居是 6 ^ 1<<2 = 2
c
static inline void __free_one_page(struct page *page,
unsigned long pfn,
struct zone *zone, unsigned int order,
int migratetype, fpi_t fpi_flags)
{
while (order < MAX_ORDER) {
buddy = find_buddy_page_pfn(page, pfn, order, &buddy_pfn); // 找到邻居page
if (!buddy) // 如果没,结束合并
goto done_merging;
del_page_from_free_list(buddy, zone, order); // 空闲的邻居页先从空闲列表里删除
combined_pfn = buddy_pfn & pfn; // 取两个的最小值
page = page + (combined_pfn - pfn); // 最小值对应的page
pfn = combined_pfn;
order++; // 更新order, 继续尝试合并
}
done_merging:
set_buddy_order(page, order); // 更新page对应的order
if (to_tail) // 将page加入到空闲列表里
add_to_free_list_tail(page, zone, order, migratetype);
else
add_to_free_list(page, zone, order, migratetype);
}
static inline struct page *find_buddy_page_pfn(struct page *page,
unsigned long pfn, unsigned int order, unsigned long *buddy_pfn)
{
unsigned long __buddy_pfn = __find_buddy_pfn(pfn, order); // 内容为 page_pfn ^ (1 << order);
struct page *buddy;
buddy = page + (__buddy_pfn - pfn);
if (buddy_pfn)
*buddy_pfn = __buddy_pfn;
if (page_is_buddy(page, buddy, order)) // 进一步检查zone, order等信息
return buddy;
return NULL;
}
static inline unsigned long __find_buddy_pfn(unsigned long page_pfn, unsigned int order)
{
return page_pfn ^ (1 << order); //找邻居的算法
}页分配
页分配的核心函数是从__alloc_pages开始,大致的调用流程如下:
c
__alloc_pages() //
prepare_alloc_pages() // 基本参数获取
get_page_from_freelist() // 遍历zone,从该zone上面空闲列表里获取page
rmqueue() // 在指定的zone上根据order和migratetype继续寻找
rmqueue_pcplist() // 先尝试从per-cpu上面的缓存里寻找
rmqueue_buddy() //
__rmqueue_smallest() //
get_page_from_free_area() // 通过order和migratetype获取空闲列表
del_page_from_free_list() // 从列表里释放页出来
expand() // 如果从更高的order获取页,则拆分的多余的页归还到较低order的空闲列表
prep_new_page() // 部分参数初始化,如果是组合页也在这里初始化。
__alloc_pages_slowpath()变量和结构体
全局变量
内核态虚拟内存空间
x86_64下虚拟内存空间布局如下 https://www.kernel.org/doc/html/latest/arch/x86/x86_64/mm.html#complete-virtual-memory-map-with-4-level-page-tables
SLAB
内核空间里的内存分配,并不一定从buddy里直接分配,而主要通过SLAB系统分配。因为许多结构体都是小于4k, 直接一页的空间太浪费了。 SLAB运行 在buddy的上层,一次性从buddy里拿多个page缓存起来,上层业务需要时,自己维护相关的列表切分出符合业务需要的size。 业务释放 内存时,也缓存起来,并不释放给buddy。提高下次分配的效率。
SLAB分两种情况,统一关联在全局链表slab_caches上面
- 固定size的,预先生成
struct kmem_cache *s, 然后通过 kmem_cache_XXX 处理。 - 运行时才确认size的, 通过 kmalloc申请, kfree释放。
常见的接口
c
// 从指定的kmem_cache里分配一个对象,
void *kmem_cache_alloc(struct kmem_cache *s, gfp_t gfpflags)
// 传入node,返回的内存是指定node的
void *kmem_cache_alloc_node(struct kmem_cache *s, gfp_t gfpflags, int node)
void *kmem_cache_alloc_lru(struct kmem_cache *s, struct list_lru *lru, gfp_t gfpflags)
// 释放对象
void kmem_cache_free(struct kmem_cache *s, void *x)
// 一次性申请size个对象,地址存在p开头的array里
int kmem_cache_alloc_bulk(struct kmem_cache *s, gfp_t flags, size_t size, void **p)
// 一次性释放size个对象, 这些对象的地址在p所指的array里
void kmem_cache_free_bulk(struct kmem_cache *s, size_t size, void **p)
// 指定所需内存大小的分配和释放
void *__kmalloc(size_t size, gfp_t flags)
void *__kmalloc_node(size_t size, gfp_t flags, int node)
void kfree(const void *object)struct kmem_cache 的变量为s,slab的分配时先从s->cpu_slab上面取, 如果没有去s->node[x]取,还是没有再从buddy系统里分配 页出来。也就是有两层缓存, 先per-cpu级,再次node级。
slab里所有的对象没有使用 且 s->node[x]->nr_partial > s->min_partial 时, 释放slab给buddy系统。
s->cpu_partial_slabs用来控制s->cpu_slab->partial上面的slab数量,当per-cpu从node上获取slab时,一次性 拿 s->cpu_partial_slabs / 2 个slab。在释放流程里,如果s->cpu_slab->partial的slab数量超过 s->cpu_partial_slabs, 则释放到s->node[x]->partial
重要的结构体如下
c
struct kmem_cache {
struct kmem_cache_cpu *cpu_slab // per-cpu, 先从这里检查是否有空闲的对象
unsigned long min_partial // node级别里最小的partial数
unsigned int size // 每个对象的size, 含元数据 ALIGN(size + (sizeof(void *) if have s->ctor), s->align)
unsigned int object_size // 真实的size, 从使用视角看
unsigned int cpu_partial // 未使用
unsigned int cpu_partial_slabs // 控制s->cpu_slab->partial 上面的slab数量
struct kmem_cache_order_objects oo // 含order和objects, order表示从buddy系统里一次分配多少页,objects代表这些内存可代表多少个对象。
struct kmem_cache_order_objects min // 分配一个对象的最小的order信息
unsigned int inuse // ALIGN(object_size, sizeof(void *))
unsigned int align // 对齐要求,一般是8
const char *name // 名字
struct kmem_cache_node *node[1024] // node级的缓冲
}
struct kmem_cache_cpu {
void **freelist;
unsigned long tid;
struct slab *slab; // 当前正在被用来分配的struct slab
struct slab *partial; // struct slab的链表, 通过next连接,
local_lock_t lock;
}
struct kmem_cache_node {
spinlock_t list_lock;
unsigned long nr_partial; // partial链表里总的slab个数
struct list_head partial; // struct slab的链表, 通过slab_list连接
atomic_long_t nr_slabs; // 从buddy系统申请到的slab个数
atomic_long_t total_objects; // 上述slab对应的对象总数
struct list_head full; // 基本不用
}
struct slab {
unsigned long __page_flags;
struct kmem_cache *slab_cache;
union {
struct {
union {
struct list_head slab_list; //通过这个字段挂在n->partial上面
struct {
struct slab *next; // per-cpu的partial链表通过这个字段连接
int slabs; // per-cpu的partial链表上面slab的数量
};
};
void *freelist;
union {
unsigned long counters;
struct {
unsigned int inuse : 16; // 已经分配出去的对象个数
unsigned int objects : 15; // 总的对象个数
unsigned int frozen : 1; // 在node上是0, 在per-cpu上是1
};
};
};
struct callback_head callback_head;
};
unsigned int __unused;
atomic_t __page_refcount;
unsigned long memcg_data;
}上述结构体整体通过图来表示关联关系 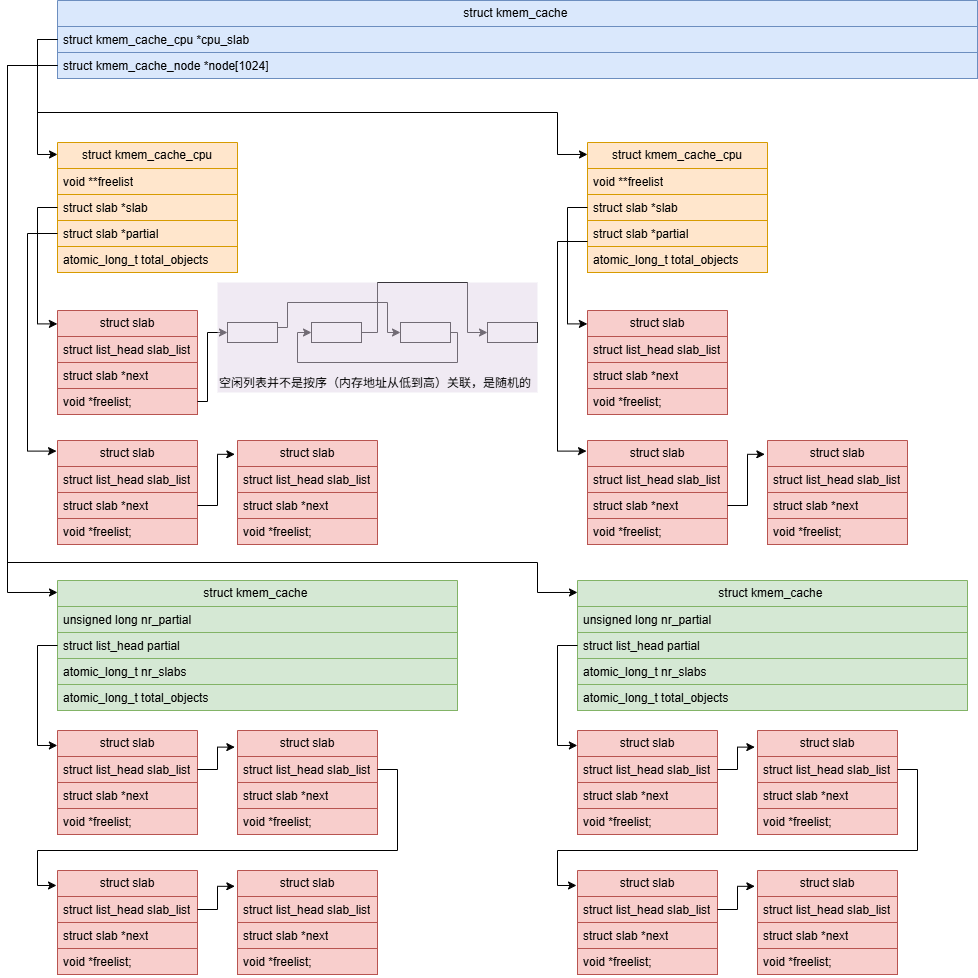
/proc/slabinfo里的数据通过如下函数统计, 更详细的信息可以在/sys/kernel/slab/找到, 每个struct kmem_cache一个文件夹。
c
void get_slabinfo(struct kmem_cache *s, struct slabinfo *sinfo)
{
unsigned long nr_slabs = 0;
unsigned long nr_objs = 0;
unsigned long nr_free = 0;
int node;
struct kmem_cache_node *n;
for_each_kmem_cache_node(s, node, n) {
nr_slabs += node_nr_slabs(n);
nr_objs += node_nr_objs(n);
nr_free += count_partial(n, count_free);
}
sinfo->active_objs = nr_objs - nr_free;
sinfo->num_objs = nr_objs;
sinfo->active_slabs = nr_slabs;
sinfo->num_slabs = nr_slabs;
sinfo->objects_per_slab = oo_objects(s->oo);
sinfo->cache_order = oo_order(s->oo);
}
static int count_free(struct slab *slab)
{
return slab->objects - slab->inuse;
}
static inline unsigned long node_nr_slabs(struct kmem_cache_node *n)
{
return atomic_long_read(&n->nr_slabs);
}
static inline unsigned long node_nr_objs(struct kmem_cache_node *n)
{
return atomic_long_read(&n->total_objects);
}在meminfo里slab分两种情况,SReclaimable(可回收)和SUnreclaim(不可回收),如果flag有 SLAB_RECLAIM_ACCOUNT则可回收。 如果系统内存紧张,可通过echo 2 > /proc/sys/vm/drop_caches 释放可回收的slab, 主要就是inode和dentry。 grep "1" /sys/kernel/slab/*/reclaim_account可查看具体哪些kmem_cache是可回收的。 slab统计的相关函数如下
c
static __always_inline void account_slab(struct slab *slab, int order,
struct kmem_cache *s, gfp_t gfp)
{
if (memcg_kmem_online() && (s->flags & SLAB_ACCOUNT))
memcg_alloc_slab_cgroups(slab, s, gfp, true);
mod_node_page_state(slab_pgdat(slab), cache_vmstat_idx(s),
PAGE_SIZE << order);
}
static __always_inline void unaccount_slab(struct slab *slab, int order,
struct kmem_cache *s)
{
if (memcg_kmem_online())
memcg_free_slab_cgroups(slab);
mod_node_page_state(slab_pgdat(slab), cache_vmstat_idx(s),
-(PAGE_SIZE << order));
}
static inline enum node_stat_item cache_vmstat_idx(struct kmem_cache *s)
{
return (s->flags & SLAB_RECLAIM_ACCOUNT) ?
NR_SLAB_RECLAIMABLE_B : NR_SLAB_UNRECLAIMABLE_B;
}VMALLOC
vmalloc是内核空间申请内存的一种方式,逻辑内存地址是连续的,但是对应的物理内存不连续。
地址区间默认为 [0xffffc90000000000, 0xffffe8ffffffffff], 开了kaslr后地址会随机化。最终的start地址为vmalloc_base
但内核模块使用vmalloc时虚拟地址区间为[0xffffffffc00000000, xffffffffff000000], 开了kaslr后start地址会随机化, 偏移量记录在静态变量module_load_offset
部分函数解释
vmalloc_huge // 如果size超过PMD_SIZE, 使用大页分配
vmalloc // 通用的分配函数,指定align 为 1
vmalloc_node // 分配函数,指定在具体的node上面分配内存
vfree // 释放函数
vmap // 只映射虚拟内存
vunmap // 取消映射
vmalloc_user // 用户态程序可访问,比如 xdp里的Ring实现
remap_vmalloc_range // 配合上面的函数,将页映射到用户程序的虚拟内存地址
is_vmalloc_addr // 判断内存地址是否属于vmalloc常见的结构体
struct vmap_area 要么挂在free_vmap_area_root, 要么挂在vmap_area_root。
一个struct vm_struct 唯一对应一个struct vmap_area
c
struct vm_struct { // 从vmalloc系统申请内存后,用该结构体记录size, 起始和终止内存地址等
struct vm_struct *next; // vmalloc_init时将已存在且通过该字段连接的vm_struct插入到vmap_area_root
void *addr; // 起始虚拟地址
unsigned long size; // 比用户实际size多增加一页大小,保护页。
unsigned long flags;
struct page **pages; // 存放页地址
unsigned int page_order; // 申请真实内存时使用的order,一般是0, 即一页一页地申请直到满足size
unsigned int nr_pages; // size(不含保护页)对应的页数
phys_addr_t phys_addr; // ioremap时记录IO设备的物理地址
const void *caller;
};
struct vmap_area {
unsigned long va_start;
unsigned long va_end;
struct rb_node rb_node; /* address sorted rbtree */
struct list_head list; /* address sorted list */
/*
* The following two variables can be packed, because
* a vmap_area object can be either:
* 1) in "free" tree (root is free_vmap_area_root)
* 2) or "busy" tree (root is vmap_area_root)
*/
union {
unsigned long subtree_max_size; /* in "free" tree */ // 空闲时用
struct vm_struct *vm; /* in "busy" tree */ // 使用时用于指向对应的struct vm_struct
};
unsigned long flags; /* mark type of vm_map_ram area */
};分配过程简述
c
__vmalloc_node_range() // 返回 vm_struct->addr
__get_vm_area_node() // 从slab里申请vm_struct, 计算size增加4k,当做保护页。不会实际分配,
alloc_vmap_area() // 从slab里申请vmap_area并完成两个结构体的关联
__alloc_vmap_area() // 从free_vmap_area_root上面找到满足size的struct vmap_area,涉及拆分,合并等操作
setup_vmalloc_vm() // start, size等信息传给struct vm_struct, 同时完成vmap_area与vm_struct的关联
insert_vmap_area() // 将新的vmap_area插入到全局列表vmap_area_root和vmap_area_list
__vmalloc_area_node() // 提前申请空间,用于存放page地址, 增加nr_vmalloc_pages
vm_area_alloc_pages() // 从buddy系统里循环申请页
vmap_pages_range() // 虚拟内存地址与真实的物理页建立映射释放过程, 在free_unmap_vmap_areavmap_area的释放是惰性的,会先挂在purge_vmap_area_root上,如果超过 最大值,然后通过定时器机器触发异步的真正释放
c
vfree() // 释放过程的主函数
remove_vm_area() //
find_unlink_vmap_area() // 通过addr在vmap_area_root里找到对应的vmap_area,并unlink
free_unmap_vmap_area() // 取消虚拟--物理之前的映射并释放vmap_area
__free_page() // 释放具体的物理页vmalloc有大致三种场景:
- 正常的通过vmalloc或相同功能的函数申请, 不仅获取虚拟内存地址,还分配对应的物理页。
- 调用者提供具体的物理页, 只通过vmalloc系统完成虚拟内存地址映射的。这里还分vmap和ioremap
- 与1类似,但同时映射到用户态程序的虚拟内存空间,用户态程序可访问
/proc/vmallocinfo里字段解释:
前两个字段 vm_struct里 start-start+size size。 (含保护页)
第三个字段 调用方函数信息vmap 代表只映射,vmalloc自身并不分配实际的物理内存phys=0x00000000dfff0000 ioremap 代表映射到的IO设备的物理地址pages=1 vmalloc N0=1 代表分配了一个物理页,是普通的vmalloc, 在node0对应的内存里分配了一页unpurged vm_area 表示惰性释放时挂在purge_vmap_area_list上面的vm_area, 还未完全释放到slab里
# head -5 /proc/vmallocinfo
0xffffaa9dc0000000-0xffffaa9dc0005000 20480 irq_init_percpu_irqstack+0xcf/0x100 vmap
0xffffaa9dc0005000-0xffffaa9dc0007000 8192 acpi_os_map_iomem+0x1c7/0x1e0 phys=0x00000000dfff0000 ioremap
0xffffaa9dc0008000-0xffffaa9dc000c000 16384 acpi_os_map_iomem+0x1c7/0x1e0 phys=0x00000000dfff0000 ioremap
0xffffaa9dc000c000-0xffffaa9dc000e000 8192 gen_pool_add_owner+0x3a/0xc0 pages=1 vmalloc N0=1
0xffffaa9dc000e000-0xffffaa9dc0010000 8192 bpf_prog_alloc_no_stats+0x37/0x240 pages=1 vmalloc N0=1如下命令计算通过vmalloc真实申请的物理内存大小。
# grep pages /proc/vmallocinfo | awk '{print $4}' | awk -F= '{sum+=$2} END{print sum*4,"KB"}'
13512 KBVmallocTotal 在x86_64下面永远是32T,没啥实际意义VmallocUsed 读取全局变量nr_vmalloc_pages, ioremap这些未实际分配的也算进去了,不准。VmallocChunk 永远是0
# grep Vmalloc /proc/meminfo
VmallocTotal: 34359738367 kB
VmallocUsed: 18352 kB
VmallocChunk: 0 kB用户态虚拟内存空间
shmem共享内存
实现了文件系统的接口,名字为tmpfs。但不同于ext4等基于文件的方式,后端是基于内存实现的。可使用 mount -t tmpfs tmpfs xxx创建一个新的文件系统。
下面是一台测试机真实的输出, /dev,/dev/shm,/run,/run/user/0都是通过共享内存实现的(/dev对应的 文件系统是devtmpfs, 它也是基于tmpfs的)。所有用户态程序都可以读写这些挂载点的文件,所以是共享的。size=4096k代表该文件系统最大是的容量是4M, 如果在mount时没指定option, 那么默认的最大容量是物理内存的 一半。
# df -hT
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs tmpfs 6.0G 0 6.0G 0% /dev/shm
tmpfs tmpfs 2.4G 8.5M 2.4G 1% /run
/dev/sda1 ext4 49G 26G 21G 55% /
tmpfs tmpfs 1.2G 4.0K 1.2G 1% /run/user/0
# grep tmpfs /proc/mounts
devtmpfs /dev devtmpfs rw,nosuid,size=4096k,nr_inodes=65536,mode=755,inode64 0 0
tmpfs /dev/shm tmpfs rw,nosuid,nodev,inode64 0 0
tmpfs /run tmpfs rw,nosuid,nodev,size=2512292k,nr_inodes=819200,mode=755,inode64 0 0
tmpfs /run/user/0 tmpfs rw,nosuid,nodev,relatime,size=1256144k,nr_inodes=314036,mode=700,inode64 0 0重要的数据结构
c
const struct address_space_operations shmem_aops // mmp后文件在内存中对应的结构体的操作函数集合
static const struct file_operations shmem_file_operations // 文件本身的操作函数集合
static const struct inode_operations shmem_inode_operations // inode元数据操作函数集合
static const struct inode_operations shmem_dir_inode_operations // dir的元数据操作函数集合
static const struct inode_operations shmem_special_inode_operations // 特殊文件的元数据操作函数集合
static const struct vm_operations_struct shmem_vm_ops // mmap文件系统里的文件时关联的操作函数集合
static const struct vm_operations_struct shmem_anon_vm_ops // mmap时对于匿名共享关联的操作函数集合
static const struct super_operations shmem_ops // 超级块的操作函数集
static struct file_system_type shmem_fs_type // 用于注册文件系统一般有两种使用方式
- mount为新的挂载点,使用起来就跟使用ext4文件系统一样
- 通过shmem_file_setup在一个只内核可见的挂载点上面申请内存(mmap anon share, ipc shm都采用这种方式)
在shmem_init()里运行shm_mnt = kern_mount(&shmem_fs_type);创建一个只内核可见的全局挂载点
用户态虚拟空间相关的结构体
c
struct mm_struct { // 每个task有个独立的mm_struct,管理该task下所有的内存布局
struct maple_tree mm_mt;
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
unsigned long mmap_base; // arch_pick_mmap_base里确定值,有随机化处理
unsigned long mmap_legacy_base; // 64位程序不使用
unsigned long mmap_compat_base;
unsigned long mmap_compat_legacy_base;
unsigned long task_size;
pgd_t *pgd; // 每个task有独立的页表, 这是根
atomic_t membarrier_state;
atomic_t mm_users;
atomic_t mm_count;
atomic_long_t pgtables_bytes;
int map_count; // mmap函数调用次数
spinlock_t page_table_lock;
struct rw_semaphore mmap_lock;
struct list_head mmlist;
unsigned long hiwater_rss;
unsigned long hiwater_vm;
unsigned long total_vm; // 单位页, 不论是否已分配
unsigned long locked_vm; // 带VM_LOCKED标志的页数
atomic64_t pinned_vm;
unsigned long data_vm; // 申请的页数,不论是否已分配
unsigned long exec_vm; // 申请的页数,不论是否已分配
unsigned long stack_vm; // 申请的页数,不论是否已分配
unsigned long def_flags;
seqcount_t write_protect_seq;
spinlock_t arg_lock;
unsigned long start_code;
unsigned long end_code;
unsigned long start_data;
unsigned long end_data;
unsigned long start_brk; // heap的起始虚拟内存地址
unsigned long brk; // heap的结束虚拟内存地址
unsigned long start_stack;
unsigned long arg_start;
unsigned long arg_end;
unsigned long env_start;
unsigned long env_end;
unsigned long saved_auxv[48];
struct percpu_counter rss_stat[4];
struct linux_binfmt *binfmt;
mm_context_t context;
unsigned long flags;
spinlock_t ioctx_lock;
struct kioctx_table *ioctx_table;
struct task_struct *owner;
struct user_namespace *user_ns;
struct file *exe_file;
struct mmu_notifier_subscriptions *notifier_subscriptions;
unsigned long numa_next_scan;
unsigned long numa_scan_offset;
int numa_scan_seq;
atomic_t tlb_flush_pending;
atomic_t tlb_flush_batched;
struct uprobes_state uprobes_state;
atomic_long_t hugetlb_usage;
struct work_struct async_put_work;
struct iommu_mm_data *iommu_mm;
unsigned long ksm_merging_pages;
unsigned long ksm_rmap_items;
struct {
struct list_head list;
unsigned long bitmap;
struct mem_cgroup *memcg;
} lru_gen;
}
struct vm_area_struct {
union {
struct {
unsigned long vm_start;
unsigned long vm_end;
};
};
struct mm_struct *vm_mm;
pgprot_t vm_page_prot;
union {
const vm_flags_t vm_flags;
vm_flags_t __vm_flags;
};
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
struct list_head anon_vma_chain;
struct anon_vma *anon_vma;
const struct vm_operations_struct *vm_ops;
unsigned long vm_pgoff; // vm_start对应的后端文件偏移量,单位是页
struct file *vm_file; // 指向mmap映射的具体文件
void *vm_private_data;
atomic_long_t swap_readahead_info;
struct mempolicy *vm_policy;
struct vma_numab_state *numab_state;
struct vm_userfaultfd_ctx vm_userfaultfd_ctx;
}
struct address_space {
struct inode *host;
struct xarray i_pages;
struct rw_semaphore invalidate_lock;
gfp_t gfp_mask;
atomic_t i_mmap_writable; // mmap时设置为共享,则加一
struct rb_root_cached i_mmap; // vm_area_struct全部插入到这个红黑根节点上面
struct rw_semaphore i_mmap_rwsem;
unsigned long nrpages;
unsigned long writeback_index;
const struct address_space_operations *a_ops;
unsigned long flags;
errseq_t wb_err;
spinlock_t private_lock;
struct list_head private_list;
void *private_data;
}mmap
mmap过程流程如下,主要是根据参数寻找合适的空闲区域(用vm_area_struct表示),并赋值vm_ops。不做实际的内存分配 动作,真正的分配是在发生page fault后发生。
arch_get_unmapped_area_topdown从最高值 (0x7ffffffff000-0x8000000-random)里搜索空闲的区域。
c
do_mmap() // 先对参数做些校验
get_unmapped_area() // 根据size寻找满足条件的空闲虚拟内存区域
// case 1: 后端是文件
file->f_op->get_unmapped_area() //
// case 2: 后端是共享内存
shmem_get_unmapped_area() //
// case 3: 匿名内存
arch_get_unmapped_area_topdown() // 内存地址从高到低找到符合要求的addr
mmap_region() // 先检查addr能否和prev,next的vm_area_struct合并,不能则新建一个
// case 1: 后端是文件
call_mmap() // 赋值vma->vm_ops为文件系统特定的操作函数集合
// case 2: 后端是共享内存
shmem_zero_setup() // 根据inode的i_nlink非0, 则vma->vm_ops = &shmem_vm_ops,否则vma->vm_ops = &shmem_anon_vm_ops
// case 3: 匿名内存
vma_set_anonymous() // vma->vm_ops = NULLstack & heap & others
heap在kernel视角里指的是[mm->start_brk, mm->brk]之前的内存区域, 最大空间受RLIMIT_DATA的控制。 vma->vm_ops = NULL, 算匿名页。 具体实现参考函数do_brk_flags
stack是向下增长,内存地址从高到低。 vma->vm_start <= vma->vm_mm->start_stack <= vma->vm_end
heap, stack 都算匿名页
code
vdso
vsyscall
page fault
mmap, brk等申请内存,并不直接分配内存。而是等程序读写时才真正分配内存。通过触发pagefault完成
用户程序通过系统调用申请内存有两种方式:
- brk 不断增加brk, 可获取匿名页
- mmap, 可申请匿名内存,映射文件当内存访问,匿名共享内存(基于tmpfs实现)
用户态内存分三种情况:
- 匿名页,进程私有
page 增加 SwapBacked 标志
内存统计增加 NR_ANON_MAPPED
folio->mapping = vma->anon_vma + PAGE_MAPPING_ANON
folio->index = linear_page_index(vma, address)
算 LRU ANON - 文件页,映射后端文件,私有时,写操作会触发cow, 单独分配页。
调用 vma->vm_ops->fault 处理, inode唯一对应一个address_space
内存统计增加 NR_FILE_PAGES
算 LRU FILE - 共享内存页, 其他也算文件页,但后端又是内存,非正常的文件。
调用 vma->vm_ops->fault 处理
page 增加 SwapBacked 标志
内存统计增加 NR_FILE_PAGES 和 NR_SHMEM
算 LRU ANON
folio->mapping 设置为 inode->i_mapping
folio->index 设置为 pgoff (相对于文件)
不会走到 mem_cgroup_charge里
文件页和共享页里的 NR_SHMEM, NR_FILE_PAGES统计, 加入到LRU的统计,都是在fault函数及其子函数里完成的。
没有NR_ANON_PAGES, 因为所有的ANON都是mapped的, 进程退出则会理解释放。 所以只有NR_ANON_MAPPED。NR_FILE_MAPPED 是NR_FILE_PAGES的子集,因为ummap文件后,文件的数据仍然存在pagecache里。并没有释放。
vma->vm_ops为空,则说明是匿名页
c
static inline bool vma_is_anonymous(struct vm_area_struct *vma)
{
return !vma->vm_ops;
}文件页和共享页rss和NR_XXX_MAPPED统计
c
// 匿名页处理
do_anonymous_page() {
inc_mm_counter(vma->vm_mm, MM_ANONPAGES); // 统计到 mm->rss_stat 里
folio_add_new_anon_rmap(folio, vma, vmf->address); // 增加到 NR_ANON_MAPPED
folio_add_lru_vma(folio, vma); // 加入到LRU统计
}
// 文件页和共享页的处理,如果mmap时是非共享且可写情况,则发生cow, 会生成匿名页。
finish_fault()
do_set_pte() {
if (write && !(vma->vm_flags & VM_SHARED)) {
// 匿名页, cow的情况
inc_mm_counter(vma->vm_mm, MM_ANONPAGES);
page_add_new_anon_rmap(page, vma, addr); // 增加到 NR_ANON_MAPPED
lru_cache_add_inactive_or_unevictable(page, vma); // 加入到LRU的统计
} else {
// 文件页或者共享页
inc_mm_counter(vma->vm_mm, mm_counter_file(page)); // 统计到 mm->rss_stat 里
page_add_file_rmap(page, vma, false); // 内存统计增加 NR_FILE_MAPPED
}
}
static inline int mm_counter_file(struct page *page)
{
if (PageSwapBacked(page))
return MM_SHMEMPAGES;
return MM_FILEPAGES;
}pagefault调用流程如下:
c
handle_page_fault() // 总入口
do_kern_addr_fault() // 处理内核态的内存地址fault
do_user_addr_fault() // 处理用户态的内存地址fault
emulate_vsyscall() // vsyscall的处理
find_vma() // 找到addr对应的vm_area_struct
handle_mm_fault() //
hugetlb_fault() // 大页内存的处理
__handle_mm_fault() // 非大页内存的处理,建立页表
handle_pte_fault() // 将page填入到pte里
do_pte_missing() //
do_anonymous_page() // 匿名页的处理
do_fault() // 文件页的处理
do_read_fault() // 如果vm flag只有读,进入该函数
finish_fault() // vmf->cow_page或者vmf->page写入pte
do_cow_fault() // 非共享的可写的话,走这里处理
finish_fault() // vmf->cow_page或者vmf->page写入pte
do_shared_fault() // 共享的内存处理
finish_fault() // vmf->cow_page或者vmf->page写入pte
do_swap_page() //
do_numa_page() //
do_wp_page() //
mem_cgroup_oom_synchronize() // 如果cgroup oom, 则进入这个函数
mm_account_fault() // 统计
pagefault_out_of_memory() // 如果系统oom,则进入这个函数execve以及初始化进程内存空间过程
fork+execve是创建新进程的通用做法,fork复制老进程的所有信息,execve通过加载新进程elf里的信息到内存完成 数据的替换,最后在调整RIP为elf的入口点。在execve里新进程的虚拟内存空间里重要的变量也确定下来。
返回用户态时设置的RIP两种情况:
- 如果有interpreter, 则RIP为interpreter的entry address
- 如果没有interpreter, 则RIP为execve参数里传入的elf文件的entry address
具体的调用流程如下:
c
do_execveat_common() // 传入执行文件名,参数,环境变量
alloc_bprm() // 分配linux_binprm结构体,含整个加载执行文件的上下文信息
bprm_mm_init() // 分配新的mm_struct, 最终会替换掉当前的
__bprm_mm_init() // 分配新的vm_area_struct, 地址区间[STACK_TOP_MAX-PAGE_SIZE, STACK_TOP_MAX]
copy_string_kernel() // 此时bprm->p = STACK_TOP_MAX - sizeof(void *),bprm->向下增长,复制文件名
copy_strings() // 继续复制env, arg的数据,并更新bprm->p
bprm_execve()
do_open_execat() // 打开可执行文件,返回 struct file
exec_binprm()
search_binary_handler() // 系统支持的所有格式逐一尝试匹配
prepare_binprm() // 读取文件的前256个字符, 方便后续识别文件格式
load_elf_binary() // elf文件会运行该函数
load_elf_phdrs() // 解析elf,获取所有program headers信息
begin_new_exec()
de_thread() // 终止其他线程,如果当前线程不是主线程,则等主线程到达退出状态后, exchange pid等信息,使当前task 变为主线程。
exec_mmap() // current->mm = bprm->mm, 并释放掉原来的
__set_task_comm() // 设置进程名
setup_new_exec()
arch_pick_mmap_layout() // 设置 mm->mmap_base = ((1UL << 47) - PAGE_SIZE) - 128M, 不考虑随机化处理的话
setup_arg_pages() // 设置 mm->arg_start = bprm->p
elf_map() // mmap映射所有elf里的type为LOAD的段,所有地址都要加0x555555554000
load_elf_interp() // 加载ld
create_elf_tables() // 在bprm->p的下方配置AUX等信息,设置 mm->arg_end mm->env_end mm->env_start
start_thread() // 修改SP为mm->start_stack,设置新的IP,返回用户态下图更清晰的描述了内存布局,从elf里加载的exe,data, bss等数据,对应的虚拟地址,并不一定是elf里指定的VirtAddr。 当elf文件的type是EXEC(静态编译,比如go),才是这样。 当type为Dyn(动态编译,大部分c/c++程序)时,会在读取到的 VirtAddr基础上都偏移0x555555554000(如果随机化处理,还会增加些随机数)。 最终的映射地址可以查看/proc/[pid]/maps。
[start_code, end_code] 指的是类型LOAD且权限含X(可执行的)的地址区间。
[start_data, end_data] 指的是end_code之后类型LOAD的地址区间。
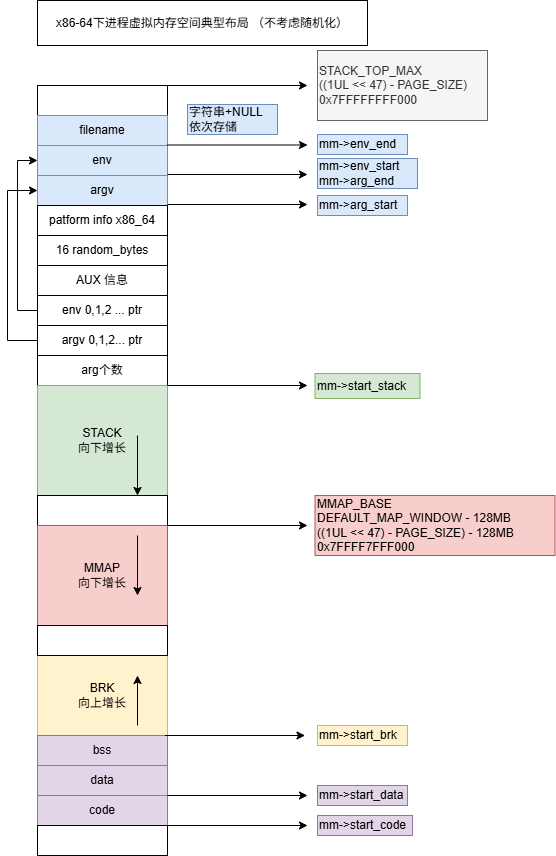
地址随机化控制参数说明: kernel.randomize_va_space 配置为0, 则关闭随机化。
在cmdline里增加norandmaps,也能达到同样的效果。