
Appearance
virtio驱动
virtio驱动指在virtio框架下实现blk,scsi,net等设备的虚拟化技术. 不管底层是什么硬件设备,在qemu都可以转换成virtio, 这样guestos只需要安装virtio驱动就可以不感知底层的实际硬件而与之交互.
常见的有virtio_blk, virtio_net, virtio_scsi等, 其核心思想是host跟guestos有一块连续的内存空间, 双方都能看见访问,称之为环. guestos将数据封装后更新avail值, hostos消费后更新used值. 这个消费可以是读取数据,也可以是写数据.
c
/* The standard layout for the ring is a continuous chunk of memory which looks
* like this. We assume num is a power of 2.
*
* struct vring
* {
* // The actual descriptors (16 bytes each)
* struct vring_desc desc[num];
*
* // A ring of available descriptor heads with free-running index.
* __virtio16 avail_flags;
* __virtio16 avail_idx;
* __virtio16 available[num];
* __virtio16 used_event_idx;
*
* // Padding to the next align boundary.
* char pad[];
*
* // A ring of used descriptor heads with free-running index.
* __virtio16 used_flags;
* __virtio16 used_idx;
* struct vring_used_elem used[num];
* __virtio16 avail_event_idx;
* };
*/
/* We publish the used event index at the end of the available ring, and vice
* versa. They are at the end for backwards compatibility. */
#define vring_used_event(vr) ((vr)->avail->ring[(vr)->num])
#define vring_avail_event(vr) (*(__virtio16 *)&(vr)->used->ring[(vr)->num])virtio_blk
任何block设备都要实现struct blk_mq_ops里定义的函数, virtio_blk也不例外
c
static const struct blk_mq_ops virtio_mq_ops = {
.queue_rq = virtio_queue_rq,
.commit_rqs = virtio_commit_rqs,
.complete = virtblk_request_done,
.init_request = virtblk_init_request,
.map_queues = virtblk_map_queues,
};一个virtio-blk盘使用一个pci设备, 受限于pci设备的总个数限制, 一台虚拟机最多挂在28个virtio-blk盘. 一个virtio-blk盘对应一个struct virtio_device
bash
crash> list device.parent -s device.kobj.name,type,bus,driver ffffa0de46076848
ffffa0de46076848
kobj.name = 0xffffa0de44c492c8 "vda1",
type = 0xffffffff93ea4d80 <part_type>,
bus = 0x0,
driver = 0x0,
ffffa0de462cadc8
kobj.name = 0xffffa0de44bd2f18 "vda",
type = 0xffffffff930e16e0 <disk_type>,
bus = 0x0,
driver = 0x0,
ffffa0de43ef4010
kobj.name = 0xffffa0e583cec078 "virtio3",
type = 0x0,
bus = 0xffffffff93ebd700 <virtio_bus>,
driver = 0xffffffffc048f000 <virtio_blk>,
ffffa0de440310d0
kobj.name = 0xffffa0de43ff3cd0 "0000:02:01.0",
type = 0xffffffff93102440 <pci_dev_type>,
bus = 0xffffffff93ea9fa0 <pci_bus_type>,
driver = 0xffffffff93ebd978 <virtio_pci_driver+152>,
ffffa0de43a450d0
kobj.name = 0xffffa0ed5fcf7210 "0000:00:05.0",
type = 0xffffffff93102440 <pci_dev_type>,
bus = 0xffffffff93ea9fa0 <pci_bus_type>,
driver = 0x0,
ffffa0e583ef0000
kobj.name = 0xffffa0de43e977b0 "pci0000:00",
type = 0x0,
bus = 0x0,
driver = 0x0,
crash>假设virtio_blk的设备为vda, 有个分区 vda1, 在vda1上面创建ext4文件系统.常见的几个结构体的关系如下: 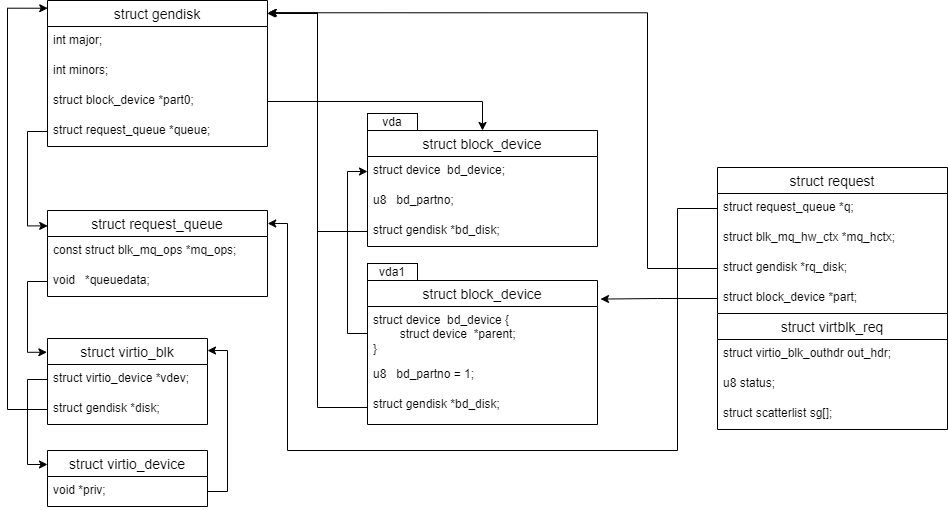 无论块设备上面有多少个分区, 都只有一个 gendisk 和 request_queue. request里指向的block_device是实际接收io的块设备, 也就是文件系统映射的设备.可以是分区
无论块设备上面有多少个分区, 都只有一个 gendisk 和 request_queue. request里指向的block_device是实际接收io的块设备, 也就是文件系统映射的设备.可以是分区
通常virtio_blk设备是单队列, virtio_queue_rq简单的将数据放入sg, 然后加入到vring里. 具体的过程如下: 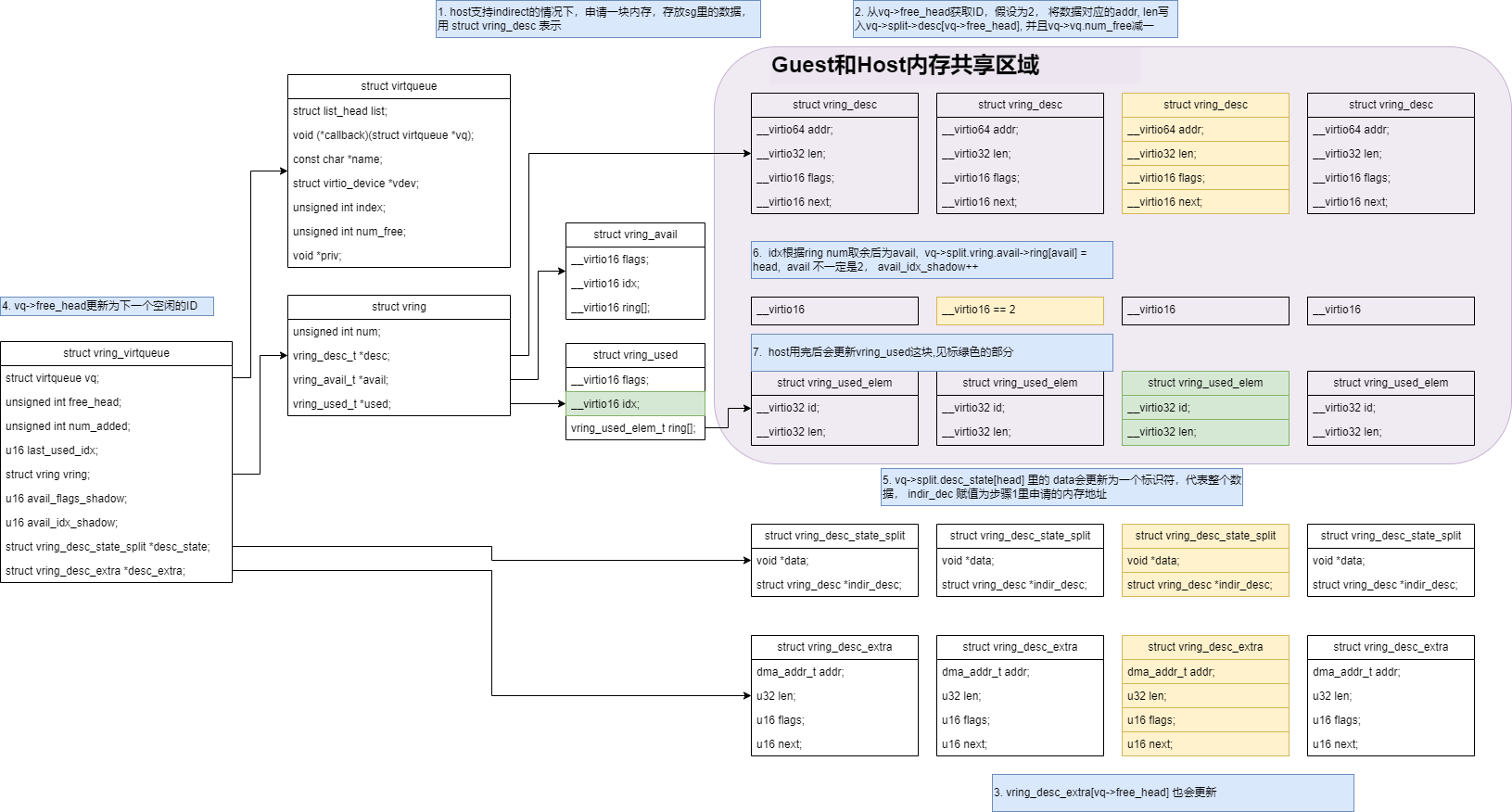 下发IO如果环满,会返回
下发IO如果环满,会返回BLK_STS_DEV_RESOURCE, block层会再次requeue
c
err = virtblk_add_req(vblk->vqs[qid].vq, vbr, vbr->sg, num);
if (err) {
virtqueue_kick(vblk->vqs[qid].vq);
/* Don't stop the queue if -ENOMEM: we may have failed to
* bounce the buffer due to global resource outage.
*/
if (err == -ENOSPC)
blk_mq_stop_hw_queue(hctx);
spin_unlock_irqrestore(&vblk->vqs[qid].lock, flags);
switch (err) {
case -ENOSPC:
return BLK_STS_DEV_RESOURCE;
case -ENOMEM:
return BLK_STS_RESOURCE;
default:
return BLK_STS_IOERR;
}
}virtio IO设备的环是全双工的, 即这个环guestos可以读写, hostos也能读写. 但net设备是一对,只用于接收数据的环和只用于发送数据的环, 便于提高效率.
当硬件消费环里的信息后(读请求的话,就把数据写入到指定内存, 写请求的话就把数据写入硬件后返回结果),通过中断通知OS,
c
for (i = 0; i < num_vqs; i++) {
callbacks[i] = virtblk_done;
snprintf(vblk->vqs[i].name, VQ_NAME_LEN, "req.%d", i);
names[i] = vblk->vqs[i].name;
}回调函数是virtblk_done, 逻辑很简单, 不断从环里取出数据,并调用blk_mq_complete_request对request完成后续的block块处理. 因为是单队列,所以只是唤醒软中断, 后续让软中断完成剩余的io动作.
c
bool blk_mq_complete_request_remote(struct request *rq)
{
WRITE_ONCE(rq->state, MQ_RQ_COMPLETE);
/*
* For a polled request, always complete locallly, it's pointless
* to redirect the completion.
*/
if (rq->cmd_flags & REQ_HIPRI)
return false;
if (blk_mq_complete_need_ipi(rq)) {
blk_mq_complete_send_ipi(rq);
return true;
}
if (rq->q->nr_hw_queues == 1) {
blk_mq_raise_softirq(rq);
return true;
}
return false;
}最终会走到virtblk_request_done, 调用blk_mq_end_request-->__blk_mq_end_request-->blk_account_io_done完成性能统计 计数工作. 这些统计数据体现在/proc/diskstats
c
void blk_mq_end_request(struct request *rq, blk_status_t error)
{
if (blk_update_request(rq, error, blk_rq_bytes(rq)))
BUG();
__blk_mq_end_request(rq, error);
}/proc/diskstats 下面两个字段不太好理解
Field 10 -- # of milliseconds spent doing I/Os
This field increases so long as field 9 is nonzero.
Field 11 -- weighted # of milliseconds spent doing I/Os
This field is incremented at each I/O start, I/O completion, I/O
merge, or read of these stats by the number of I/Os in progress
(field 9) times the number of milliseconds spent doing I/O since the
last update of this field. This can provide an easy measure of both
I/O completion time and the backlog that may be accumulating.Field 10 对应 part_stat_add(req->part, nsecs[sgrp], now - req->start_time_ns);now - req->start_time_ns 指的是从request生成到最终完成的总耗时(包括IO调度耗时和驱动层耗时)
Field 11 对应 update_io_ticks(req->part, jiffies, true); 从代码上看其实只是统计了块设备处于 工作状态(即处理IO)的时间.
假设这个设备只能串行处理IO, 那么 Field 11 除以 io总数 可以估算出每个io在硬件驱动层的耗时, 如果能并发处理IO 那么这样计算的结果就不准确了
c
void blk_account_io_start(struct request *rq)
{
if (!blk_do_io_stat(rq))
return;
/* passthrough requests can hold bios that do not have ->bi_bdev set */
if (rq->bio && rq->bio->bi_bdev)
rq->part = rq->bio->bi_bdev;
else
rq->part = rq->rq_disk->part0;
part_stat_lock();
update_io_ticks(rq->part, jiffies, false);
part_stat_unlock();
}
void blk_account_io_done(struct request *req, u64 now)
{
/*
* Account IO completion. flush_rq isn't accounted as a
* normal IO on queueing nor completion. Accounting the
* containing request is enough.
*/
if (req->part && blk_do_io_stat(req) &&
!(req->rq_flags & RQF_FLUSH_SEQ)) {
const int sgrp = op_stat_group(req_op(req));
part_stat_lock();
update_io_ticks(req->part, jiffies, true);
part_stat_inc(req->part, ios[sgrp]);
part_stat_add(req->part, nsecs[sgrp], now - req->start_time_ns);
part_stat_unlock();
}
}
static void update_io_ticks(struct block_device *part, unsigned long now,
bool end)
{
unsigned long stamp;
again:
stamp = READ_ONCE(part->bd_stamp);
if (unlikely(time_after(now, stamp))) {
if (likely(cmpxchg(&part->bd_stamp, stamp, now) == stamp))
__part_stat_add(part, io_ticks, end ? now - stamp : 1);
}
if (part->bd_partno) {
part = bdev_whole(part);
goto again;
}
}virtio_scsi
virtio_scsi 实现了struct scsi_host_template里定义的函数
c
static const struct blk_mq_ops scsi_mq_ops = {
.get_budget = scsi_mq_get_budget,
.put_budget = scsi_mq_put_budget,
.queue_rq = scsi_queue_rq,
.commit_rqs = scsi_commit_rqs,
.complete = scsi_complete,
.timeout = scsi_timeout,
#ifdef CONFIG_BLK_DEBUG_FS
.show_rq = scsi_show_rq,
#endif
.init_request = scsi_mq_init_request,
.exit_request = scsi_mq_exit_request,
.initialize_rq_fn = scsi_initialize_rq,
.cleanup_rq = scsi_cleanup_rq,
.busy = scsi_mq_lld_busy,
.map_queues = scsi_map_queues,
.init_hctx = scsi_init_hctx,
.poll = scsi_mq_poll,
.set_rq_budget_token = scsi_mq_set_rq_budget_token,
.get_rq_budget_token = scsi_mq_get_rq_budget_token,
};
static struct scsi_host_template virtscsi_host_template = {
.module = THIS_MODULE,
.name = "Virtio SCSI HBA",
.proc_name = "virtio_scsi",
.this_id = -1,
.cmd_size = sizeof(struct virtio_scsi_cmd),
.queuecommand = virtscsi_queuecommand,
.commit_rqs = virtscsi_commit_rqs,
.change_queue_depth = virtscsi_change_queue_depth,
.eh_abort_handler = virtscsi_abort,
.eh_device_reset_handler = virtscsi_device_reset,
.eh_timed_out = virtscsi_eh_timed_out,
.slave_alloc = virtscsi_device_alloc,
.dma_boundary = UINT_MAX,
.map_queues = virtscsi_map_queues,
.track_queue_depth = 1,
};通常scsi仅需要一个PCI设备, 然后所有的virtio-scsi都可以挂在这个PCI设备. 这样虚拟机能挂载的盘非常多.与virtio-blk 更多的对比,参见 https://www.qemu.org/2021/01/19/virtio-blk-scsi-configuration/
两个virtio-scsi盘 sda sdb 都挂在 00:0f.0 这个PCI设备上面,即 scsi 控制器
bash
# lspci
00:00.0 Host bridge: Intel Corporation 440FX - 82441FX PMC [Natoma] (rev 02)
00:01.0 ISA bridge: Intel Corporation 82371SB PIIX3 ISA [Natoma/Triton II]
00:02.0 VGA compatible controller: VMware SVGA II Adapter
00:03.0 Non-VGA unclassified device: Red Hat, Inc. Virtio network device
00:04.0 System peripheral: InnoTek Systemberatung GmbH VirtualBox Guest Service
00:05.0 Multimedia audio controller: Intel Corporation 82801AA AC'97 Audio Controller (rev 01)
00:06.0 USB controller: Apple Inc. KeyLargo/Intrepid USB
00:07.0 Bridge: Intel Corporation 82371AB/EB/MB PIIX4 ACPI (rev 08)
00:0f.0 SCSI storage controller: Red Hat, Inc. Virtio SCSI (rev 01)
# ls -rlt /sys/block/
total 0
lrwxrwxrwx 1 root root 0 Jul 31 21:29 sda -> ../devices/pci0000:00/0000:00:0f.0/virtio1/host0/target0:0:0/0:0:0:0/block/sda
lrwxrwxrwx 1 root root 0 Jul 31 21:29 sdb -> ../devices/pci0000:00/0000:00:0f.0/virtio1/host0/target0:0:1/0:0:1:0/block/sdblsscsi输出的第一列四个数字分别表示 host:channel:target:lun
bash
# lsscsi
[0:0:0:0] disk VBOX HARDDISK 1.0 /dev/sda
[0:0:1:0] disk VBOX HARDDISK 1.0 /dev/sdb挂在同一个host下面的设备,共享IO下发通道. 比如host 0分配的4个队列,也就是可以并行地 把io下发到这4条通道上面. sda, sdb 都在host 0上面, 那么并不是 sda, sdb 各自有4个通道, 而是sda, sdb 都在使用host 0的这4个通道. 所以性能上应该比virtio-blk差一些.
一个host对应一个struct virtio_device
bash
crash> list device.parent -s device.kobj.name,type,bus,driver ffff88eac67875c8
ffff88eac67875c8
kobj.name = 0xffff88eac0e11f60 "sda1",
type = 0xffffffffbb0ee280 <part_type>,
bus = 0x0,
driver = 0x0,
ffff88eac6786f48
kobj.name = 0xffff88eac0e11340 "sda",
type = 0xffffffffbb0edea0 <disk_type>,
bus = 0x0,
driver = 0x0,
ffff88eac09a71a0
kobj.name = 0xffff88eac087aa20 "0:0:0:0",
type = 0xffffffffbc0ea9a0 <scsi_dev_type>,
bus = 0xffffffffbc0ea580 <scsi_bus_type>,
driver = 0xffffffffc038a380 <sd_template>,
ffff88eac63cec28
kobj.name = 0xffff88eac619ce80 "target0:0:0",
type = 0xffffffffbc0e9d40 <scsi_target_type>,
bus = 0xffffffffbc0ea580 <scsi_bus_type>,
driver = 0x0,
ffff88eac6c3d290
kobj.name = 0xffff88eac0e11d78 "host0",
type = 0xffffffffbc0e9ae0 <scsi_host_type>,
bus = 0xffffffffbc0ea580 <scsi_bus_type>,
driver = 0x0,
ffff88eac0d86010
kobj.name = 0xffff88eac0349198 "virtio1",
type = 0x0,
bus = 0xffffffffbc0d0420 <virtio_bus>,
driver = 0xffffffffc02b70e0 <virtio_scsi_driver>,
ffff88eac036d0c8
kobj.name = 0xffff88eac0bfeed0 "0000:00:04.0",
type = 0xffffffffbb1164e0 <pci_dev_type>,
bus = 0xffffffffbc0bc8e0 <pci_bus_type>,
driver = 0xffffffffbc0d0668 <virtio_pci_driver+136>,
ffff88eaf424ac00
kobj.name = 0xffff88eac0bfe790 "pci0000:00",
type = 0x0,
bus = 0x0,
driver = 0x0,
crash>假设virtio_scsi的设备为sda, 有个分区 sda1, 在sda1上面创建ext4文件系统.常见的几个结构体的关系如下: 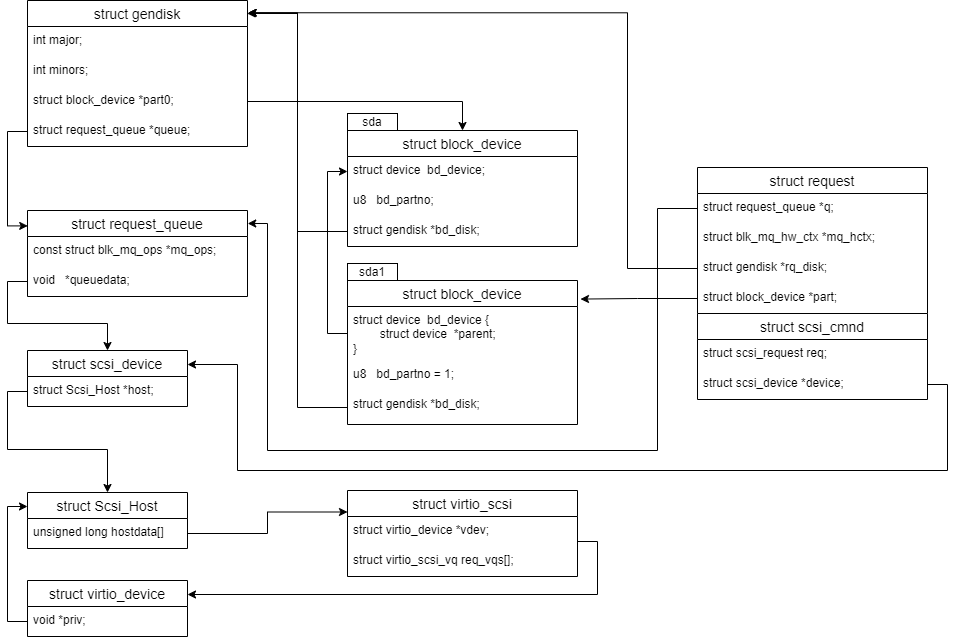
virtio-scsi设备通常有三种类型的队列, ctrl 用于发送控制指令, 比如reset, abort等. event用于事件通知,比如 新发现一个新的virtio-scsi设备,卸载一个设备等. request是用于底层完IO(读或者写)后通知OS的, OS可以继续完成 剩余的IO动作. 这块的处理跟virtio-blk基本一样.
c
callbacks[0] = virtscsi_ctrl_done;
callbacks[1] = virtscsi_event_done;
names[0] = "control";
names[1] = "event";
for (i = VIRTIO_SCSI_VQ_BASE; i < num_vqs; i++) {
callbacks[i] = virtscsi_req_done;
names[i] = "request";
}典型的下发IO的函数调用如下:
TIME: 23:15:46.464569 -> 23:15:46.464689 PID/TID: 3497/3497 (kworker/u16:2 kworker/u16:2)
CPU DURATION | FUNCTION GRAPH
--- -------- | --------------
7) | → virtscsi_queuecommand [virtio_scsi] shost=0xffff8eea471f8000 sc=0xffff8eea48f71f08
7) | → virtscsi_add_cmd [virtio_scsi] vq=0xffff8eea471f8b08 cmd=0xffff8eea48f720c0 req_size=51 resp_size=108 kick=true
7) 6.18µs | ↔ __virtscsi_add_cmd [virtio_scsi] vq=0xffff8eea47072e00 cmd=0xffff8eea48f720c0 req_size=51 resp_size=108 ret=0
7) 62.197µs | ← virtscsi_add_cmd [virtio_scsi] ret=0
7) 71.073µs | ← virtscsi_queuecommand [virtio_scsi] ret=0
scsi_dispatch_cmd+0x90
scsi_queue_rq+0x1ae
__blk_mq_try_issue_directly+0x168
blk_mq_plug_issue_direct+0x71
blk_mq_flush_plug_list+0x145
__blk_flush_plug+0x102
blk_finish_plug+0x25
wb_writeback+0x291
wb_do_writeback+0x22a
wb_workfn+0x5e
process_one_work+0x1e5
worker_thread+0x50
kthread+0xe0
ret_from_fork+0x2c如果virtscsi_add_cmd 返回错误, 且不是EIO, 那么都转换成SCSI_MLQUEUE_HOST_BUSY并向上传递, 这个会影响整个控制器下面所有的virtio-scsi 设备短暂地停止接收文件系统层下发的IO,当前的IO会再次requeue.
c
if (ret == -EIO) {
cmd->resp.cmd.response = VIRTIO_SCSI_S_BAD_TARGET;
spin_lock_irqsave(&req_vq->vq_lock, flags);
virtscsi_complete_cmd(vscsi, cmd);
spin_unlock_irqrestore(&req_vq->vq_lock, flags);
} else if (ret != 0) {
return SCSI_MLQUEUE_HOST_BUSY;
}virtscsi_event_done 只是简单点将work插入到system_freezable_wq这个workqueue_struct里. 所以这是一个异步 操作. 最终kworder进程里会调用virtscsi_handle_event处理.
c
static void virtscsi_handle_event(struct work_struct *work)
{
struct virtio_scsi_event_node *event_node =
container_of(work, struct virtio_scsi_event_node, work);
struct virtio_scsi *vscsi = event_node->vscsi;
struct virtio_scsi_event *event = &event_node->event;
if (event->event &
cpu_to_virtio32(vscsi->vdev, VIRTIO_SCSI_T_EVENTS_MISSED)) {
event->event &= ~cpu_to_virtio32(vscsi->vdev,
VIRTIO_SCSI_T_EVENTS_MISSED);
virtscsi_rescan_hotunplug(vscsi);
scsi_scan_host(virtio_scsi_host(vscsi->vdev));
}
switch (virtio32_to_cpu(vscsi->vdev, event->event)) {
case VIRTIO_SCSI_T_NO_EVENT:
break;
case VIRTIO_SCSI_T_TRANSPORT_RESET:
virtscsi_handle_transport_reset(vscsi, event);
break;
case VIRTIO_SCSI_T_PARAM_CHANGE:
virtscsi_handle_param_change(vscsi, event);
break;
default:
pr_err("Unsupport virtio scsi event %x\n", event->event);
}
virtscsi_kick_event(vscsi, event_node);
}
static void virtscsi_handle_transport_reset(struct virtio_scsi *vscsi,
struct virtio_scsi_event *event)
{
struct scsi_device *sdev;
struct Scsi_Host *shost = virtio_scsi_host(vscsi->vdev);
unsigned int target = event->lun[1];
unsigned int lun = (event->lun[2] << 8) | event->lun[3];
switch (virtio32_to_cpu(vscsi->vdev, event->reason)) {
case VIRTIO_SCSI_EVT_RESET_RESCAN:
if (lun == 0) {
scsi_scan_target(&shost->shost_gendev, 0, target,
SCAN_WILD_CARD, SCSI_SCAN_INITIAL);
} else {
scsi_add_device(shost, 0, target, lun);
}
break;
case VIRTIO_SCSI_EVT_RESET_REMOVED:
sdev = scsi_device_lookup(shost, 0, target, lun);
if (sdev) {
scsi_remove_device(sdev);
scsi_device_put(sdev);
} else {
pr_err("SCSI device %d 0 %d %d not found\n",
shost->host_no, target, lun);
}
break;
default:
pr_info("Unsupport virtio scsi event reason %x\n", event->reason);
}
}virtio_net
一个virtio_net的设备对应一个网卡, 使用一个PCI设备.常见的几个结构体的关系如下: 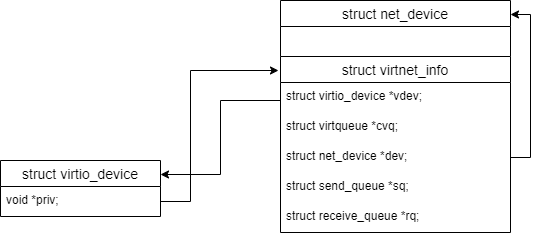
net_device, virtio_device, pci_dev 这些结构体都会嵌入`struct device",并通过 它连接起来形成层次关系。举例如下:
crash> net_device.dev -xo ffff9d2250511000
struct net_device {
[ffff9d2250511580] struct device dev;
}
crash> list device.parent -s device.kobj.name,bus,driver ffff9d2250511580
ffff9d2250511580
kobj.name = 0xffff9d22a0d942d8 "eth0",
bus = 0x0,
driver = 0x0,
ffff9d2243367010
kobj.name = 0xffff9d22a142bdd8 "virtio0",
bus = 0xffffffff836cc2c0 <virtio_bus>,
driver = 0xffffffffc03212e0 <virtio_net_driver>,
ffff9d22417f20c8
kobj.name = 0xffff9d22418209e0 "0000:00:03.0",
bus = 0xffffffff836b74a0 <pci_bus_type>,
driver = 0xffffffff836cc508 <virtio_pci_driver+136>,
ffff9d22417ea000
kobj.name = 0xffff9d2241820f20 "pci0000:00",
bus = 0x0,
driver = 0x0,典型的接收流程里, virtnet_poll 是napi里的回调函数, 网络这块为了提高效率,当中断上报时 暂时关闭中断, 然后使用poll机制不停地从网卡ring环里取数据, 直到无数据可取或者已取的数据包 个数达到预算上限. free_old_xmit_skbs 是从与之结对的发送队列里不停地获取描述符, 这些都是 底层设备已处理完后发送动作的skb, 就是在这里对发送方向的skb完成最终的释放. receive_mergeable里通过__napi_alloc_skb申请一块内存,用skb表示 然后将环里的信息copy到这个skb里. 继续通过napi_gro_receive 送到上层协议栈里.
bash
TIME: 23:18:31.292206 -> 23:18:31.292354 PID/TID: 0/0 (swapper/7 swapper/7)
CPU DURATION | FUNCTION GRAPH
--- -------- | --------------
7) | → virtnet_poll [virtio_net] napi=0xffff954dda295808 budget=64
7) 3.43µs | ↔ free_old_xmit_skbs [virtio_net] sq=0xffff954dda293800 in_napi=true ret=void
7) 734ns | ↔ netif_tx_wake_queue dev_queue=0xffff954be0850800 ret=void
7) | → virtnet_receive [virtio_net] rq=0xffff954dda295800 budget=64 xdp_xmit=0xffffbe01c0260eb4
7) | → receive_buf [virtio_net] vi=0xffff954bc74b7980 rq=0xffff954dda295800 buf=0xffff954d27a1bc00 len=102 ctx=0x600
7) | → receive_mergeable [virtio_net] dev=0xffff954bc74b7000 vi=0xffff954bc74b7980 rq=0xffff954dda295800 buf=0xffff954d27a1bc00 ctx=0x600
7) | → page_to_skb [virtio_net] vi=0xffff954bc74b7980 rq=0xffff954dda295800 page=0xfffff5eb899e8600 offset=15360 len=102
7) 3.966µs | ↔ __napi_alloc_skb napi=0xffff954dda295808 len=128 gfp_mask=2592 ret=0xffff954bc889fb00
7) 397ns | ↔ skb_put skb=0xffff954bc889fb00 len=90 ret=0xffff954d11ad0840
7) 6.664µs | ← page_to_skb [virtio_net] ret=0xffff954bc889fb00
7) 8.39µs | ← receive_mergeable [virtio_net] ret=0xffff954bc889fb00
7) | → napi_gro_receive napi=0xffff954dda295808 skb=0xffff954bc889fb00
7) | → dev_gro_receive napi=0xffff954dda295808 skb=0xffff954bc889fb00
7) 426ns | ↔ gro_list_prepare head=0xffff954dda295848 skb=0xffff954bc889fb00 ret=void
7) 6.84µs | ↔ inet_gro_receive head=0xffff954dda295848 skb=0xffff954bc889fb00 ret=0x0
7) 10.135µs | ← dev_gro_receive ret=3
7) 11.352µs | ← napi_gro_receive ret=3
7) 23.306µs | ← receive_buf [virtio_net] ret=void
7) 25.584µs | ← virtnet_receive [virtio_net] ret=1
7) | → napi_complete_done n=0xffff954dda295808 work_done=1
7) | → netif_receive_skb_list_internal head=0xffff954dda295910
7) 482ns | ↔ skb_defer_rx_timestamp skb=0xffff954bc889fb00 ret=false
7) | → __netif_receive_skb_list_core head=0xffff954dda295910 pfmemalloc=false
7) | → ip_list_rcv head=0xffffbe01c0260dc8 pt=0xffffffff9af75820 orig_dev=0xffff954bc74b7000
7) 602ns | ↔ ip_rcv_core skb=0xffff954bc889fb00 net=0xffffffff9c77ee00 ret=0xffff954bc889fb00
7) 80.367µs | ↔ ip_sublist_rcv head=0xffffbe01c0260d48 dev=0xffff954bc74b7000 net=0xffffffff9c77ee00 ret=void
7) 83.457µs | ← ip_list_rcv ret=void
7) 85.548µs | ← __netif_receive_skb_list_core ret=void
7) 88.63µs | ← netif_receive_skb_list_internal ret=void
7) 89.843µs | ← napi_complete_done ret=true
7) 138.342µs | ← virtnet_poll [virtio_net] ret=1
__napi_poll+0x2a
net_rx_action+0x233
__do_softirq+0xca
__irq_exit_rcu+0xa1
common_interrupt+0x80
asm_common_interrupt+0x22
default_idle+0xb
default_idle_call+0x2e
cpuidle_idle_call+0x125
do_idle+0x78
cpu_startup_entry+0x19
start_secondary+0x10d
secondary_startup_64_no_verify+0xe5try_fill_recv函数用于提前在接收队列里填充描述符(也可以理解为申请到内存区域), 这样底层就可以把数据放到指定的内存地址. 发送队列不存在这个问题. 因为skb已经在上层的协议栈分配好了.
发送方向如果环里的空闲的描述符少于19个,说明底层取包速度太慢存在性能瓶颈,guestos会主动调用netif_stop_subqueue停止 该队列. 后续的发包可能会在tc层丢弃.
c
static netdev_tx_t start_xmit(struct sk_buff *skb, struct net_device *dev)
{
/* If running out of space, stop queue to avoid getting packets that we
* are then unable to transmit.
* An alternative would be to force queuing layer to requeue the skb by
* returning NETDEV_TX_BUSY. However, NETDEV_TX_BUSY should not be
* returned in a normal path of operation: it means that driver is not
* maintaining the TX queue stop/start state properly, and causes
* the stack to do a non-trivial amount of useless work.
* Since most packets only take 1 or 2 ring slots, stopping the queue
* early means 16 slots are typically wasted.
*/
if (sq->vq->num_free < 2+MAX_SKB_FRAGS) {
netif_stop_subqueue(dev, qnum);
if (!use_napi &&
unlikely(!virtqueue_enable_cb_delayed(sq->vq))) {
/* More just got used, free them then recheck. */
free_old_xmit_skbs(sq, false);
if (sq->vq->num_free >= 2+MAX_SKB_FRAGS) {
netif_start_subqueue(dev, qnum);
virtqueue_disable_cb(sq->vq);
}
}
}
return NETDEV_TX_OK;
}